diff --git a/.dev_scripts/gather_models.py b/.dev_scripts/gather_models.py
index 58919fd444..e09dc9e230 100644
--- a/.dev_scripts/gather_models.py
+++ b/.dev_scripts/gather_models.py
@@ -3,17 +3,28 @@
Usage:
python gather_models.py ${root_path} ${out_dir}
+
+Example:
+python gather_models.py \
+work_dirs/pgd_r101_caffe_fpn_gn-head_3x4_4x_kitti-mono3d \
+work_dirs/pgd_r101_caffe_fpn_gn-head_3x4_4x_kitti-mono3d
+
+Note that before running the above command, rename the directory with the
+config name if you did not use the default directory name, create
+a corresponding directory 'pgd' under the above path and put the used config
+into it.
"""
import argparse
import glob
import json
-import mmcv
import shutil
import subprocess
-import torch
from os import path as osp
+import mmcv
+import torch
+
# build schedule look-up table to automatically find the final model
SCHEDULES_LUT = {
'_1x_': 12,
@@ -25,6 +36,7 @@
'_6x_': 73,
'_50e_': 50,
'_80e_': 80,
+ '_100e_': 100,
'_150e_': 150,
'_200e_': 200,
'_250e_': 250,
@@ -35,16 +47,18 @@
RESULTS_LUT = {
'coco': ['bbox_mAP', 'segm_mAP'],
'nus': ['pts_bbox_NuScenes/NDS', 'NDS'],
- 'kitti-3d-3class': [
- 'KITTI/Overall_3D_moderate',
- 'Overall_3D_moderate',
- ],
+ 'kitti-3d-3class': ['KITTI/Overall_3D_moderate', 'Overall_3D_moderate'],
'kitti-3d-car': ['KITTI/Car_3D_moderate_strict', 'Car_3D_moderate_strict'],
'lyft': ['score'],
'scannet_seg': ['miou'],
's3dis_seg': ['miou'],
'scannet': ['mAP_0.50'],
- 'sunrgbd': ['mAP_0.50']
+ 'sunrgbd': ['mAP_0.50'],
+ 'kitti-mono3d': [
+ 'img_bbox/KITTI/Car_3D_AP40_moderate_strict',
+ 'Car_3D_AP40_moderate_strict'
+ ],
+ 'nus-mono3d': ['img_bbox_NuScenes/NDS', 'NDS']
}
@@ -144,15 +158,13 @@ def main():
# and parse the best performance
model_infos = []
for used_config in used_configs:
- exp_dir = osp.join(models_root, used_config)
-
# get logs
- log_json_path = glob.glob(osp.join(exp_dir, '*.log.json'))[0]
- log_txt_path = glob.glob(osp.join(exp_dir, '*.log'))[0]
+ log_json_path = glob.glob(osp.join(models_root, '*.log.json'))[0]
+ log_txt_path = glob.glob(osp.join(models_root, '*.log'))[0]
model_performance = get_best_results(log_json_path)
final_epoch = model_performance['epoch']
final_model = 'epoch_{}.pth'.format(final_epoch)
- model_path = osp.join(exp_dir, final_model)
+ model_path = osp.join(models_root, final_model)
# skip if the model is still training
if not osp.exists(model_path):
@@ -181,7 +193,7 @@ def main():
model_name = model['config'].split('/')[-1].rstrip(
'.py') + '_' + model['model_time']
publish_model_path = osp.join(model_publish_dir, model_name)
- trained_model_path = osp.join(models_root, model['config'],
+ trained_model_path = osp.join(models_root,
'epoch_{}.pth'.format(model['epochs']))
# convert model
@@ -190,11 +202,10 @@ def main():
# copy log
shutil.copy(
- osp.join(models_root, model['config'], model['log_json_path']),
+ osp.join(models_root, model['log_json_path']),
osp.join(model_publish_dir, f'{model_name}.log.json'))
shutil.copy(
- osp.join(models_root, model['config'],
- model['log_json_path'].rstrip('.json')),
+ osp.join(models_root, model['log_json_path'].rstrip('.json')),
osp.join(model_publish_dir, f'{model_name}.log'))
# copy config to guarantee reproducibility
diff --git a/.dev_scripts/test_benchmark.sh b/.dev_scripts/test_benchmark.sh
index f020d7ff9e..6223fb1303 100644
--- a/.dev_scripts/test_benchmark.sh
+++ b/.dev_scripts/test_benchmark.sh
@@ -25,11 +25,11 @@ GPUS=8 GPUS_PER_NODE=8 CPUS_PER_TASK=5 ./tools/slurm_test.sh $PARTITION fcos3d_r
$CHECKPOINT_DIR/configs/fcos3d/fcos3d_r101_caffe_fpn_gn-head_dcn_2x8_1x_nus-mono3d.py/latest.pth --eval map \
2>&1|tee $CHECKPOINT_DIR/configs/fcos3d/fcos3d_r101_caffe_fpn_gn-head_dcn_2x8_1x_nus-mono3d.py/FULL_LOG.txt &
-echo 'configs/fp16/hv_second_secfpn_fp16_6x8_80e_kitti-3d-3class.py' &
-mkdir -p $CHECKPOINT_DIR/configs/fp16/hv_second_secfpn_fp16_6x8_80e_kitti-3d-3class.py
-GPUS=8 GPUS_PER_NODE=8 CPUS_PER_TASK=5 ./tools/slurm_test.sh $PARTITION hv_second_secfpn_fp16_6x8_80e_kitti-3d-3class configs/fp16/hv_second_secfpn_fp16_6x8_80e_kitti-3d-3class.py \
-$CHECKPOINT_DIR/configs/fp16/hv_second_secfpn_fp16_6x8_80e_kitti-3d-3class.py/latest.pth --eval map \
-2>&1|tee $CHECKPOINT_DIR/configs/fp16/hv_second_secfpn_fp16_6x8_80e_kitti-3d-3class.py/FULL_LOG.txt &
+echo 'configs/second/hv_second_secfpn_fp16_6x8_80e_kitti-3d-3class.py' &
+mkdir -p $CHECKPOINT_DIR/configs/second/hv_second_secfpn_fp16_6x8_80e_kitti-3d-3class.py
+GPUS=8 GPUS_PER_NODE=8 CPUS_PER_TASK=5 ./tools/slurm_test.sh $PARTITION hv_second_secfpn_fp16_6x8_80e_kitti-3d-3class configs/second/hv_second_secfpn_fp16_6x8_80e_kitti-3d-3class.py \
+$CHECKPOINT_DIR/configs/second/hv_second_secfpn_fp16_6x8_80e_kitti-3d-3class.py/latest.pth --eval map \
+2>&1|tee $CHECKPOINT_DIR/configs/second/hv_second_secfpn_fp16_6x8_80e_kitti-3d-3class.py/FULL_LOG.txt &
echo 'configs/free_anchor/hv_pointpillars_regnet-1.6gf_fpn_sbn-all_free-anchor_strong-aug_4x8_3x_nus-3d.py' &
mkdir -p $CHECKPOINT_DIR/configs/free_anchor/hv_pointpillars_regnet-1.6gf_fpn_sbn-all_free-anchor_strong-aug_4x8_3x_nus-3d.py
diff --git a/.dev_scripts/train_benchmark.sh b/.dev_scripts/train_benchmark.sh
index 7655ab174e..5d3da9aa01 100644
--- a/.dev_scripts/train_benchmark.sh
+++ b/.dev_scripts/train_benchmark.sh
@@ -25,11 +25,11 @@ GPUS=8 GPUS_PER_NODE=8 CPUS_PER_TASK=5 ./tools/slurm_train.sh $PARTITION fcos3d_
$CHECKPOINT_DIR/configs/fcos3d/fcos3d_r101_caffe_fpn_gn-head_dcn_2x8_1x_nus-mono3d.py --cfg-options checkpoint_config.max_keep_ckpts=1 \
2>&1|tee $CHECKPOINT_DIR/configs/fcos3d/fcos3d_r101_caffe_fpn_gn-head_dcn_2x8_1x_nus-mono3d.py/FULL_LOG.txt &
-echo 'configs/fp16/hv_second_secfpn_fp16_6x8_80e_kitti-3d-3class.py' &
-mkdir -p $CHECKPOINT_DIR/configs/fp16/hv_second_secfpn_fp16_6x8_80e_kitti-3d-3class.py
-GPUS=8 GPUS_PER_NODE=8 CPUS_PER_TASK=5 ./tools/slurm_train.sh $PARTITION hv_second_secfpn_fp16_6x8_80e_kitti-3d-3class configs/fp16/hv_second_secfpn_fp16_6x8_80e_kitti-3d-3class.py \
-$CHECKPOINT_DIR/configs/fp16/hv_second_secfpn_fp16_6x8_80e_kitti-3d-3class.py --cfg-options checkpoint_config.max_keep_ckpts=1 \
-2>&1|tee $CHECKPOINT_DIR/configs/fp16/hv_second_secfpn_fp16_6x8_80e_kitti-3d-3class.py/FULL_LOG.txt &
+echo 'configs/second/hv_second_secfpn_fp16_6x8_80e_kitti-3d-3class.py' &
+mkdir -p $CHECKPOINT_DIR/configs/second/hv_second_secfpn_fp16_6x8_80e_kitti-3d-3class.py
+GPUS=8 GPUS_PER_NODE=8 CPUS_PER_TASK=5 ./tools/slurm_train.sh $PARTITION hv_second_secfpn_fp16_6x8_80e_kitti-3d-3class configs/second/hv_second_secfpn_fp16_6x8_80e_kitti-3d-3class.py \
+$CHECKPOINT_DIR/configs/second/hv_second_secfpn_fp16_6x8_80e_kitti-3d-3class.py --cfg-options checkpoint_config.max_keep_ckpts=1 \
+2>&1|tee $CHECKPOINT_DIR/configs/second/hv_second_secfpn_fp16_6x8_80e_kitti-3d-3class.py/FULL_LOG.txt &
echo 'configs/free_anchor/hv_pointpillars_regnet-1.6gf_fpn_sbn-all_free-anchor_strong-aug_4x8_3x_nus-3d.py' &
mkdir -p $CHECKPOINT_DIR/configs/free_anchor/hv_pointpillars_regnet-1.6gf_fpn_sbn-all_free-anchor_strong-aug_4x8_3x_nus-3d.py
diff --git a/.github/ISSUE_TEMPLATE/error-report.md b/.github/ISSUE_TEMPLATE/error-report.md
index 5ec0318463..703a7d44b7 100644
--- a/.github/ISSUE_TEMPLATE/error-report.md
+++ b/.github/ISSUE_TEMPLATE/error-report.md
@@ -28,7 +28,7 @@ A placeholder for the command.
**Environment**
-1. Please run `python mmdet3d/utils/collect_env.py` to collect necessary environment infomation and paste it here.
+1. Please run `python mmdet3d/utils/collect_env.py` to collect necessary environment information and paste it here.
2. You may add addition that may be helpful for locating the problem, such as
- How you installed PyTorch [e.g., pip, conda, source]
- Other environment variables that may be related (such as `$PATH`, `$LD_LIBRARY_PATH`, `$PYTHONPATH`, etc.)
diff --git a/.github/ISSUE_TEMPLATE/reimplementation_questions.md b/.github/ISSUE_TEMPLATE/reimplementation_questions.md
index 8e36e80912..9c17fb6794 100644
--- a/.github/ISSUE_TEMPLATE/reimplementation_questions.md
+++ b/.github/ISSUE_TEMPLATE/reimplementation_questions.md
@@ -46,7 +46,7 @@ A placeholder for the config.
**Environment**
-1. Please run `python mmdet3d/utils/collect_env.py` to collect necessary environment infomation and paste it here.
+1. Please run `python mmdet3d/utils/collect_env.py` to collect necessary environment information and paste it here.
2. You may add addition that may be helpful for locating the problem, such as
- How you installed PyTorch [e.g., pip, conda, source]
- Other environment variables that may be related (such as `$PATH`, `$LD_LIBRARY_PATH`, `$PYTHONPATH`, etc.)
diff --git a/.pre-commit-config.yaml b/.pre-commit-config.yaml
index 8a4b61cb77..5bd88c5a27 100644
--- a/.pre-commit-config.yaml
+++ b/.pre-commit-config.yaml
@@ -3,12 +3,8 @@ repos:
rev: 3.8.3
hooks:
- id: flake8
- - repo: https://github.com/asottile/seed-isort-config
- rev: v2.2.0
- hooks:
- - id: seed-isort-config
- - repo: https://github.com/timothycrosley/isort
- rev: 5.0.2
+ - repo: https://github.com/PyCQA/isort
+ rev: 5.10.1
hooks:
- id: isort
- repo: https://github.com/pre-commit/mirrors-yapf
@@ -43,3 +39,9 @@ repos:
hooks:
- id: docformatter
args: ["--in-place", "--wrap-descriptions", "79"]
+ - repo: https://github.com/open-mmlab/pre-commit-hooks
+ rev: v0.2.0 # Use the ref you want to point at
+ hooks:
+ - id: check-algo-readme
+ - id: check-copyright
+ args: ["mmdet3d"] # replace the dir_to_check with your expected directory to check
diff --git a/README.md b/README.md
index 0080bbcd39..178c20ae0c 100644
--- a/README.md
+++ b/README.md
@@ -25,16 +25,12 @@
[](https://github.com/open-mmlab/mmdetection3d/blob/master/LICENSE)
-**News**: We released the codebase v0.18.1.
+**News**: We released the codebase v1.0.0rc0.
-In addition, we have preliminarily supported several new models on the [v1.0.0.dev0](https://github.com/open-mmlab/mmdetection3d/tree/v1.0.0.dev0) branch, including [DGCNN](https://github.com/open-mmlab/mmdetection3d/blob/v1.0.0.dev0/configs/dgcnn/README.md), [SMOKE](https://github.com/open-mmlab/mmdetection3d/blob/v1.0.0.dev0/configs/smoke/README.md) and [PGD](https://github.com/open-mmlab/mmdetection3d/blob/v1.0.0.dev0/configs/pgd/README.md).
-
-Note: We are going through large refactoring to provide simpler and more unified usage of many modules. Thus, few features will be added to the master branch in the following months.
+Note: We are going through large refactoring to provide simpler and more unified usage of many modules.
The compatibilities of models are broken due to the unification and simplification of coordinate systems. For now, most models are benchmarked with similar performance, though few models are still being benchmarked.
-You can start experiments with [v1.0.0.dev0](https://github.com/open-mmlab/mmdetection3d/tree/v1.0.0.dev0) if you are interested. Please note that our new features will only be supported in v1.0.0 branch afterward.
-
In the [nuScenes 3D detection challenge](https://www.nuscenes.org/object-detection?externalData=all&mapData=all&modalities=Any) of the 5th AI Driving Olympics in NeurIPS 2020, we obtained the best PKL award and the second runner-up by multi-modality entry, and the best vision-only results.
Code and models for the best vision-only method, [FCOS3D](https://arxiv.org/abs/2104.10956), have been released. Please stay tuned for [MoCa](https://arxiv.org/abs/2012.12741).
@@ -87,11 +83,9 @@ This project is released under the [Apache 2.0 license](LICENSE).
## Changelog
-v0.18.1 was released in 1/2/2022.
+v1.0.0rc0 was released in 18/2/2022.
Please refer to [changelog.md](docs/en/changelog.md) for details and release history.
-For branch v1.0.0.dev0, please refer to [changelog_v1.0.md](https://github.com/Tai-Wang/mmdetection3d/blob/v1.0.0.dev0-changelog/docs/changelog_v1.0.md) for our latest features and more details.
-
## Benchmark and model zoo
Supported methods and backbones are shown in the below table.
@@ -102,6 +96,8 @@ Support backbones:
- [x] PointNet (CVPR'2017)
- [x] PointNet++ (NeurIPS'2017)
- [x] RegNet (CVPR'2020)
+- [x] DGCNN (TOG'2019)
+- [x] DLA (CVPR'2018)
Support methods
@@ -121,25 +117,31 @@ Support methods
- [x] [Group-Free-3D (ICCV'2021)](configs/groupfree3d/README.md)
- [x] [ImVoxelNet (WACV'2022)](configs/imvoxelnet/README.md)
- [x] [PAConv (CVPR'2021)](configs/paconv/README.md)
-
-| | ResNet | ResNeXt | SENet |PointNet++ | HRNet | RegNetX | Res2Net |
-|--------------------|:--------:|:--------:|:--------:|:---------:|:-----:|:--------:|:-----:|
-| SECOND | ☐ | ☐ | ☐ | ✗ | ☐ | ✓ | ☐ |
-| PointPillars | ☐ | ☐ | ☐ | ✗ | ☐ | ✓ | ☐ |
-| FreeAnchor | ☐ | ☐ | ☐ | ✗ | ☐ | ✓ | ☐ |
-| VoteNet | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
-| H3DNet | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
-| 3DSSD | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
-| Part-A2 | ☐ | ☐ | ☐ | ✗ | ☐ | ✓ | ☐ |
-| MVXNet | ☐ | ☐ | ☐ | ✗ | ☐ | ✓ | ☐ |
-| CenterPoint | ☐ | ☐ | ☐ | ✗ | ☐ | ✓ | ☐ |
-| SSN | ☐ | ☐ | ☐ | ✗ | ☐ | ✓ | ☐ |
-| ImVoteNet | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
-| FCOS3D | ✓ | ☐ | ☐ | ✗ | ☐ | ☐ | ☐ |
-| PointNet++ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
-| Group-Free-3D | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
-| ImVoxelNet | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ |
-| PAConv | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
+- [x] [DGCNN (TOG'2019)](configs/dgcnn/README.md)
+- [x] [SMOKE (CVPRW'2020)](configs/smoke/README.md)
+- [x] [PGD (CoRL'2021)](configs/pgd/README.md)
+
+| | ResNet | ResNeXt | SENet |PointNet++ |DGCNN | HRNet | RegNetX | Res2Net | DLA |
+|--------------------|:--------:|:--------:|:--------:|:---------:|:---------:|:-----:|:--------:|:-----:|:---:|
+| SECOND | ☐ | ☐ | ☐ | ✗ | ✗ | ☐ | ✓ | ☐ | ✗
+| PointPillars | ☐ | ☐ | ☐ | ✗ | ✗ | ☐ | ✓ | ☐ | ✗
+| FreeAnchor | ☐ | ☐ | ☐ | ✗ | ✗ | ☐ | ✓ | ☐ | ✗
+| VoteNet | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗
+| H3DNet | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗
+| 3DSSD | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗
+| Part-A2 | ☐ | ☐ | ☐ | ✗ | ✗ | ☐ | ✓ | ☐ | ✗
+| MVXNet | ☐ | ☐ | ☐ | ✗ | ✗ | ☐ | ✓ | ☐ | ✗
+| CenterPoint | ☐ | ☐ | ☐ | ✗ | ✗ | ☐ | ✓ | ☐ | ✗
+| SSN | ☐ | ☐ | ☐ | ✗ | ✗ | ☐ | ✓ | ☐ | ✗
+| ImVoteNet | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗
+| FCOS3D | ✓ | ☐ | ☐ | ✗ | ✗ | ☐ | ☐ | ☐ | ✗
+| PointNet++ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗
+| Group-Free-3D | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗
+| ImVoxelNet | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗
+| PAConv | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗
+| DGCNN | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗
+| SMOKE | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓
+| PGD | ✓ | ☐ | ☐ | ✗ | ✗ | ☐ | ☐ | ☐ | ✗
Other features
- [x] [Dynamic Voxelization](configs/dynamic_voxelization/README.md)
diff --git a/README_zh-CN.md b/README_zh-CN.md
index e4931c2a74..85fa01f3de 100644
--- a/README_zh-CN.md
+++ b/README_zh-CN.md
@@ -25,16 +25,12 @@
[](https://github.com/open-mmlab/mmdetection3d/blob/master/LICENSE)
-**新闻**: 我们发布了版本 v0.18.1.
+**新闻**: 我们发布了版本 v1.0.0rc0.
-另外,我们在 [v1.0.0.dev0](https://github.com/open-mmlab/mmdetection3d/tree/v1.0.0.dev0) 分支初步支持了多个新模型,包括 [DGCNN](https://github.com/open-mmlab/mmdetection3d/blob/v1.0.0.dev0/configs/dgcnn/README.md), [SMOKE](https://github.com/open-mmlab/mmdetection3d/blob/v1.0.0.dev0/configs/smoke/README.md) 和 [PGD](https://github.com/open-mmlab/mmdetection3d/blob/v1.0.0.dev0/configs/pgd/README.md)。
-
-说明:我们正在进行大规模的重构,以提供对许多模块更简单、更统一的使用。因此,在接下来的几个月里,很少有功能会添加到主分支中。
+说明:我们正在进行大规模的重构,以提供对许多模块更简单、更统一的使用。
由于坐标系的统一和简化,模型的兼容性会受到影响。目前,大多数模型都以类似的性能对齐了精度,但仍有少数模型在进行基准测试。
-如果您感兴趣,可以开始使用 [v1.0.0.dev0](https://github.com/open-mmlab/mmdetection3d/tree/v1.0.0.dev0) 分支进行实验。请注意,我们的新功能将只支持在 v1.0.0 分支。
-
在第三届 [nuScenes 3D 检测挑战赛](https://www.nuscenes.org/object-detection?externalData=all&mapData=all&modalities=Any)(第五届 AI Driving Olympics, NeurIPS 2020)中,我们获得了最佳 PKL 奖、第三名和最好的纯视觉的结果,相关的代码和模型将会在不久后发布。
最好的纯视觉方法 [FCOS3D](https://arxiv.org/abs/2104.10956) 的代码和模型已经发布。请继续关注我们的多模态检测器 [MoCa](https://arxiv.org/abs/2012.12741)。
@@ -87,11 +83,9 @@ MMDetection3D 是一个基于 PyTorch 的目标检测开源工具箱, 下一代
## 更新日志
-最新的版本 v0.18.1 在 2022.2.1 发布。
+最新的版本 v1.0.0rc0 在 2022.2.18 发布。
如果想了解更多版本更新细节和历史信息,请阅读[更新日志](docs/zh_cn/changelog.md)。
-对于分支 [v1.0.0.dev0](https://github.com/open-mmlab/mmdetection3d/tree/v1.0.0.dev0) ,请参考 [v1.0 更新日志](https://github.com/Tai-Wang/mmdetection3d/blob/v1.0.0.dev0-changelog/docs/changelog_v1.0.md) 来了解我们的最新功能和更多细节。
-
## 基准测试和模型库
测试结果和模型可以在[模型库](docs/zh_cn/model_zoo.md)中找到。
@@ -101,6 +95,8 @@ MMDetection3D 是一个基于 PyTorch 的目标检测开源工具箱, 下一代
- [x] PointNet (CVPR'2017)
- [x] PointNet++ (NeurIPS'2017)
- [x] RegNet (CVPR'2020)
+- [x] DGCNN (TOG'2019)
+- [x] DLA (CVPR'2018)
已支持的算法:
@@ -120,25 +116,31 @@ MMDetection3D 是一个基于 PyTorch 的目标检测开源工具箱, 下一代
- [x] [Group-Free-3D (ICCV'2021)](configs/groupfree3d/README.md)
- [x] [ImVoxelNet (WACV'2022)](configs/imvoxelnet/README.md)
- [x] [PAConv (CVPR'2021)](configs/paconv/README.md)
-
-| | ResNet | ResNeXt | SENet |PointNet++ | HRNet | RegNetX | Res2Net |
-|--------------------|:--------:|:--------:|:--------:|:---------:|:-----:|:--------:|:-----:|
-| SECOND | ☐ | ☐ | ☐ | ✗ | ☐ | ✓ | ☐ |
-| PointPillars | ☐ | ☐ | ☐ | ✗ | ☐ | ✓ | ☐ |
-| FreeAnchor | ☐ | ☐ | ☐ | ✗ | ☐ | ✓ | ☐ |
-| VoteNet | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
-| H3DNet | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
-| 3DSSD | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
-| Part-A2 | ☐ | ☐ | ☐ | ✗ | ☐ | ✓ | ☐ |
-| MVXNet | ☐ | ☐ | ☐ | ✗ | ☐ | ✓ | ☐ |
-| CenterPoint | ☐ | ☐ | ☐ | ✗ | ☐ | ✓ | ☐ |
-| SSN | ☐ | ☐ | ☐ | ✗ | ☐ | ✓ | ☐ |
-| ImVoteNet | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
-| FCOS3D | ✓ | ☐ | ☐ | ✗ | ☐ | ☐ | ☐ |
-| PointNet++ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
-| Group-Free-3D | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
-| ImVoxelNet | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ |
-| PAConv | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ |
+- [x] [DGCNN (TOG'2019)](configs/dgcnn/README.md)
+- [x] [SMOKE (CVPRW'2020)](configs/smoke/README.md)
+- [x] [PGD (CoRL'2021)](configs/pgd/README.md)
+
+| | ResNet | ResNeXt | SENet |PointNet++ |DGCNN | HRNet | RegNetX | Res2Net | DLA |
+|--------------------|:--------:|:--------:|:--------:|:---------:|:---------:|:-----:|:--------:|:-----:|:---:|
+| SECOND | ☐ | ☐ | ☐ | ✗ | ✗ | ☐ | ✓ | ☐ | ✗
+| PointPillars | ☐ | ☐ | ☐ | ✗ | ✗ | ☐ | ✓ | ☐ | ✗
+| FreeAnchor | ☐ | ☐ | ☐ | ✗ | ✗ | ☐ | ✓ | ☐ | ✗
+| VoteNet | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗
+| H3DNet | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗
+| 3DSSD | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗
+| Part-A2 | ☐ | ☐ | ☐ | ✗ | ✗ | ☐ | ✓ | ☐ | ✗
+| MVXNet | ☐ | ☐ | ☐ | ✗ | ✗ | ☐ | ✓ | ☐ | ✗
+| CenterPoint | ☐ | ☐ | ☐ | ✗ | ✗ | ☐ | ✓ | ☐ | ✗
+| SSN | ☐ | ☐ | ☐ | ✗ | ✗ | ☐ | ✓ | ☐ | ✗
+| ImVoteNet | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗
+| FCOS3D | ✓ | ☐ | ☐ | ✗ | ✗ | ☐ | ☐ | ☐ | ✗
+| PointNet++ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗
+| Group-Free-3D | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗
+| ImVoxelNet | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗
+| PAConv | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗
+| DGCNN | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗
+| SMOKE | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓
+| PGD | ✓ | ☐ | ☐ | ✗ | ✗ | ☐ | ☐ | ☐ | ✗
其他特性
- [x] [Dynamic Voxelization](configs/dynamic_voxelization/README.md)
diff --git a/configs/3dssd/README.md b/configs/3dssd/README.md
index 5d3c0a9aeb..579ed25cd3 100644
--- a/configs/3dssd/README.md
+++ b/configs/3dssd/README.md
@@ -1,21 +1,20 @@
# 3DSSD: Point-based 3D Single Stage Object Detector
-## Introduction
+> [3DSSD: Point-based 3D Single Stage Object Detector](https://arxiv.org/abs/2002.10187)
-We implement 3DSSD and provide the results and checkpoints on KITTI datasets.
+## Abstract
-```
-@inproceedings{yang20203dssd,
- author = {Zetong Yang and Yanan Sun and Shu Liu and Jiaya Jia},
- title = {3DSSD: Point-based 3D Single Stage Object Detector},
- booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
- year = {2020}
-}
-```
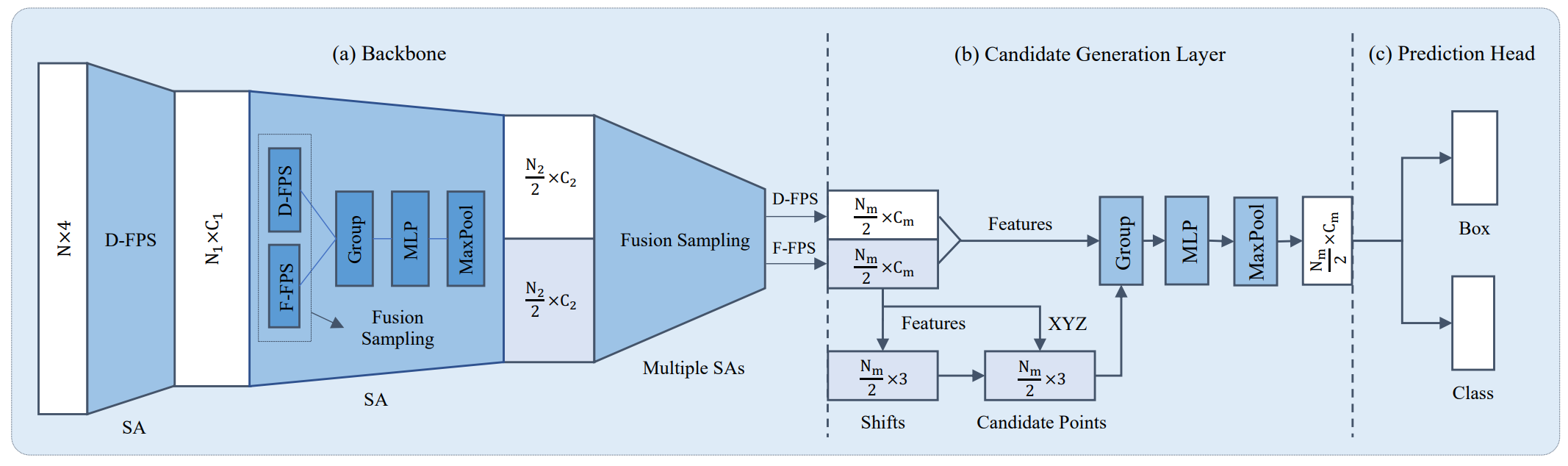
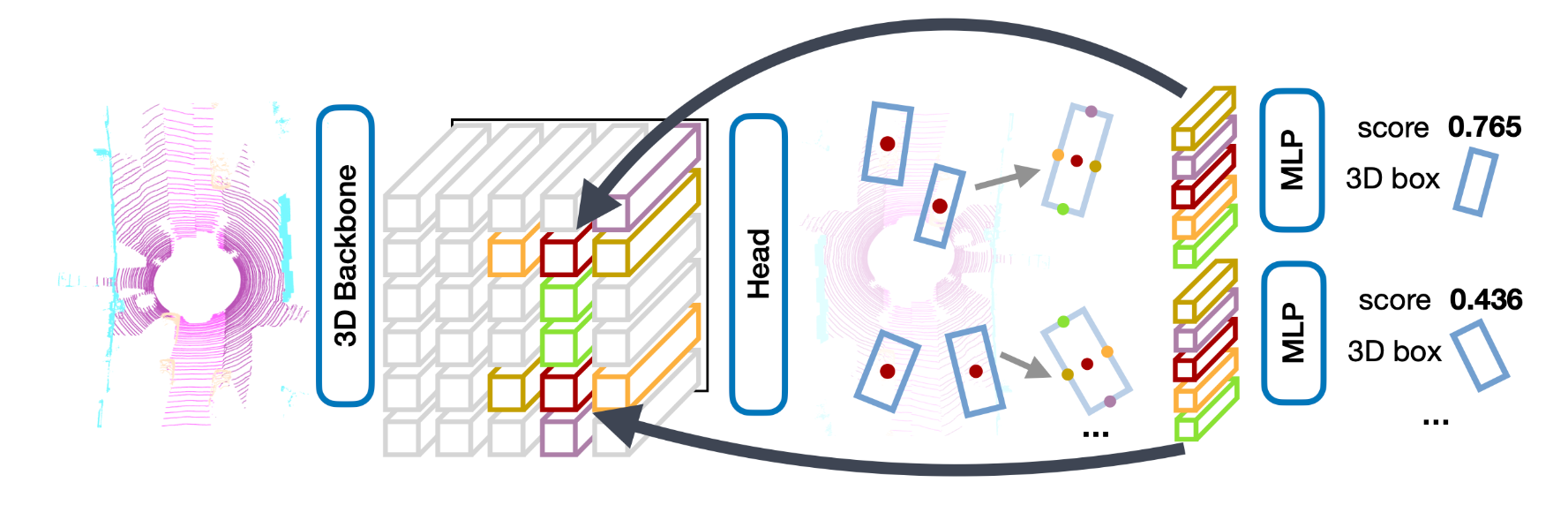
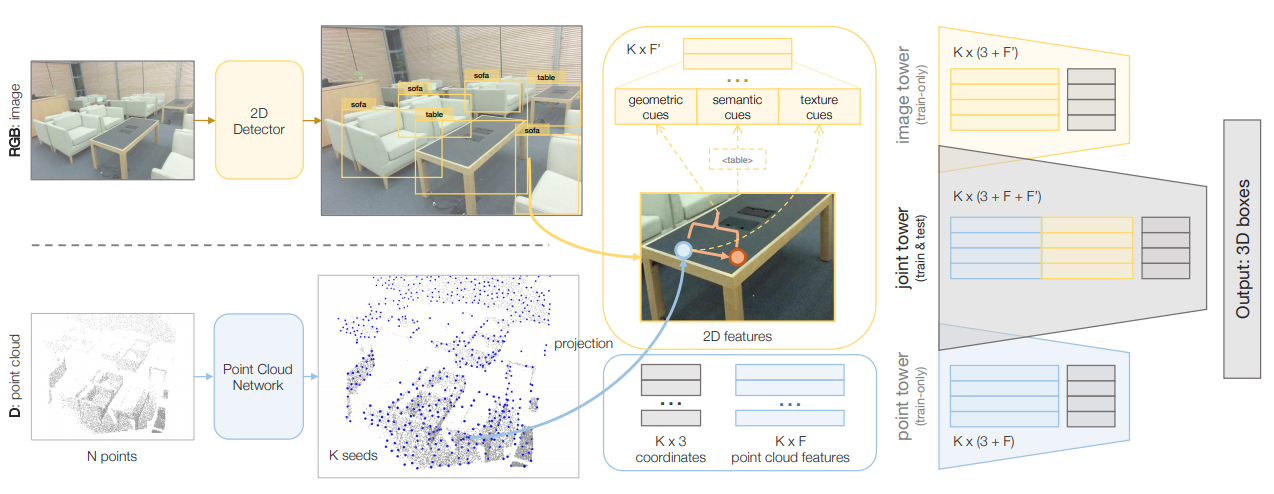
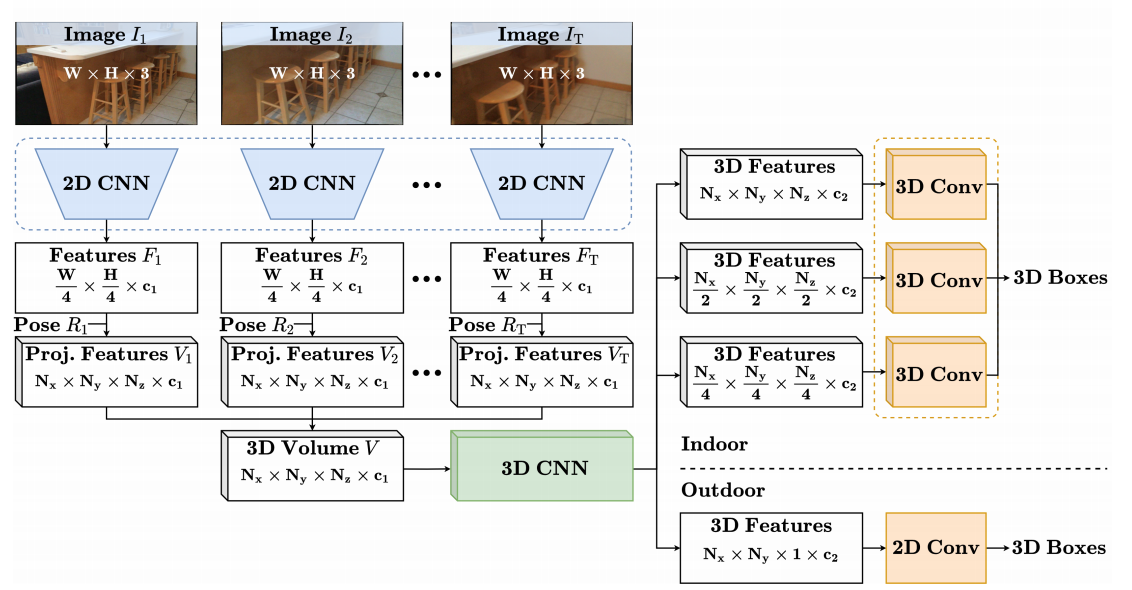
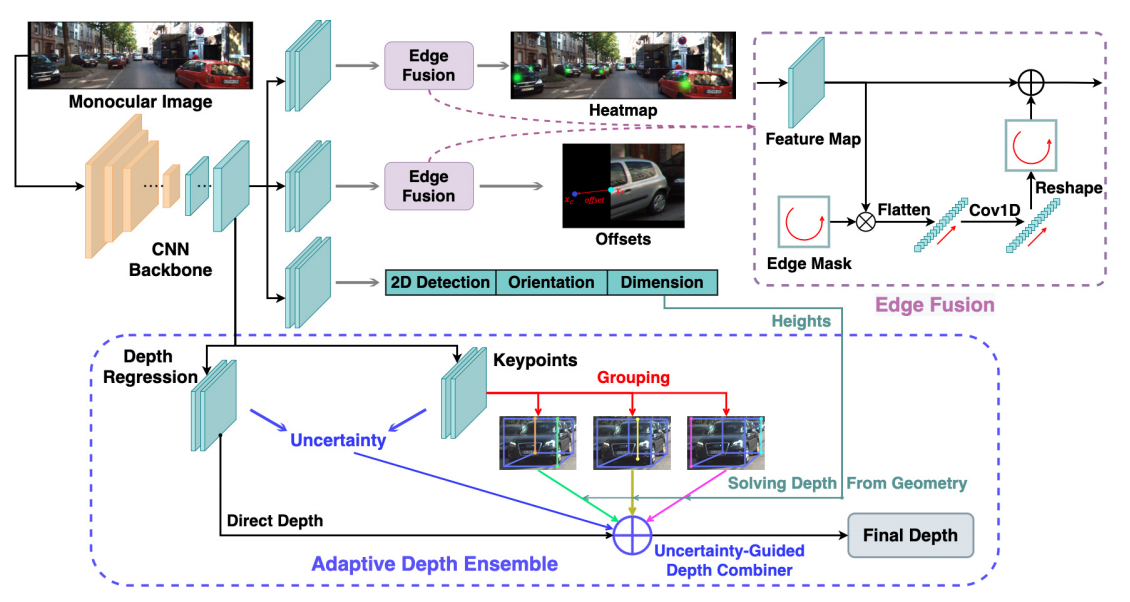
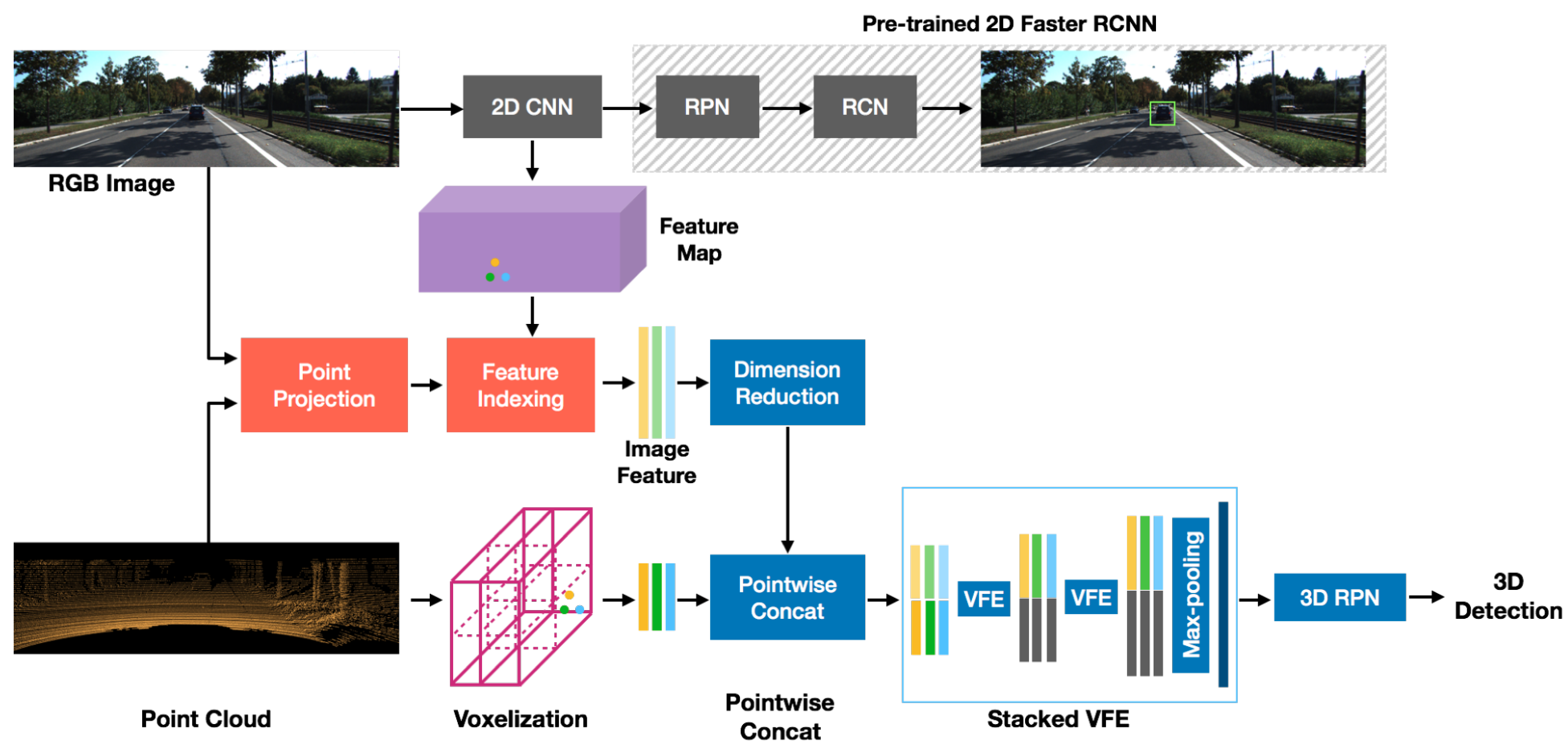
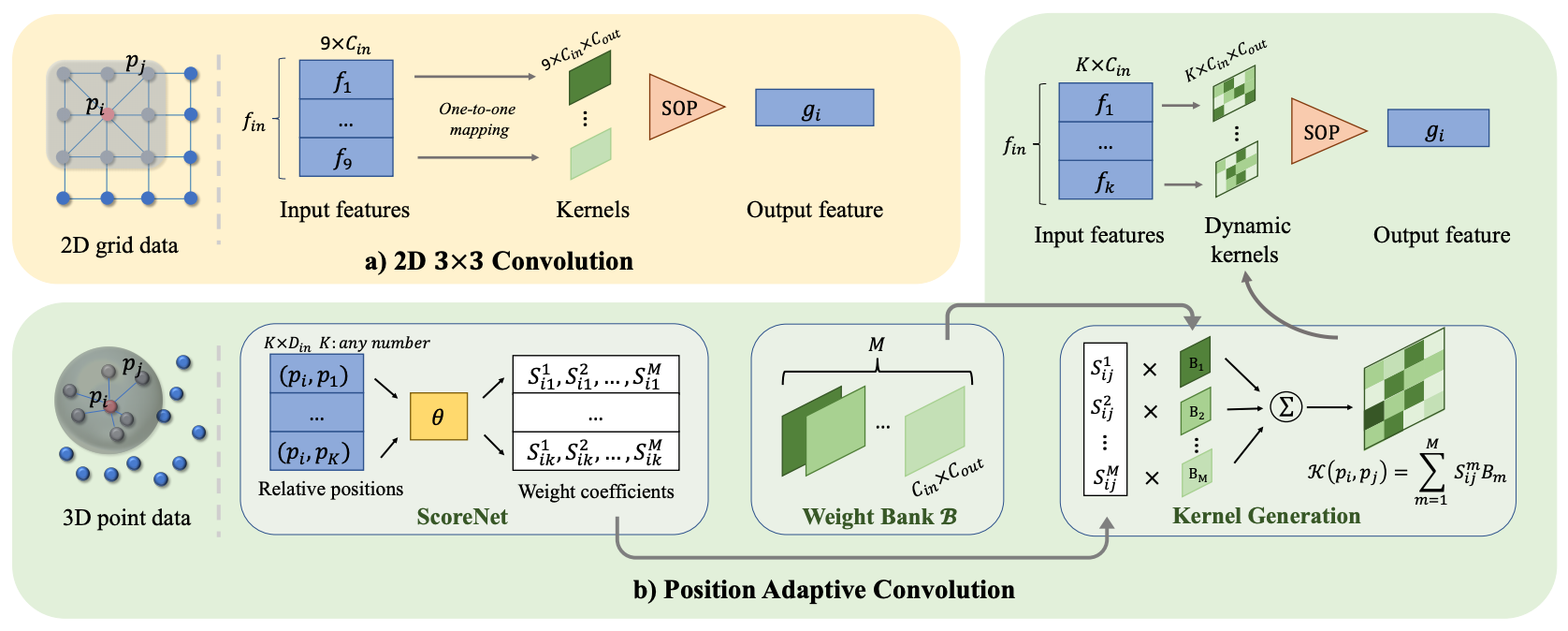
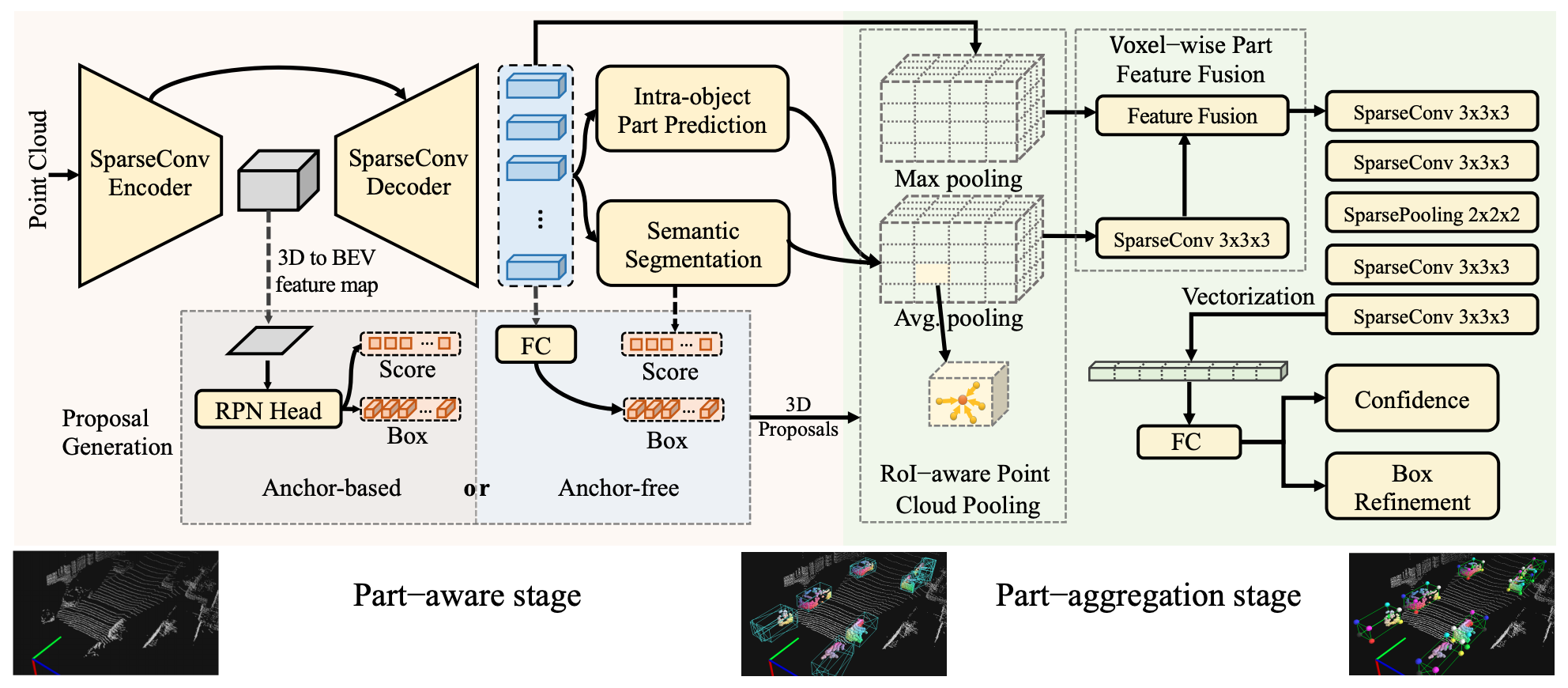
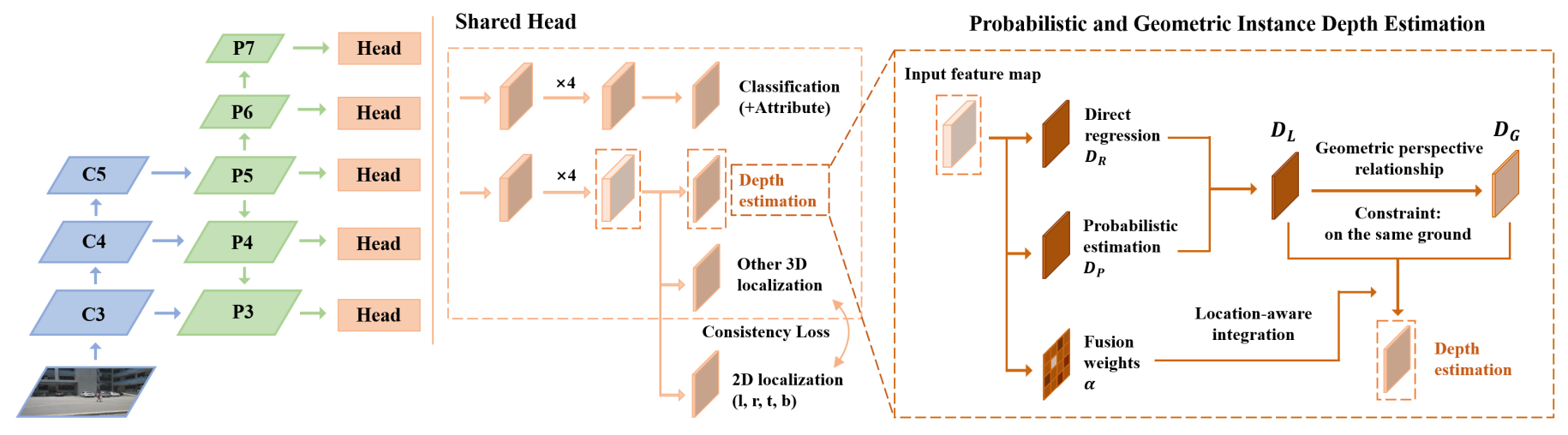
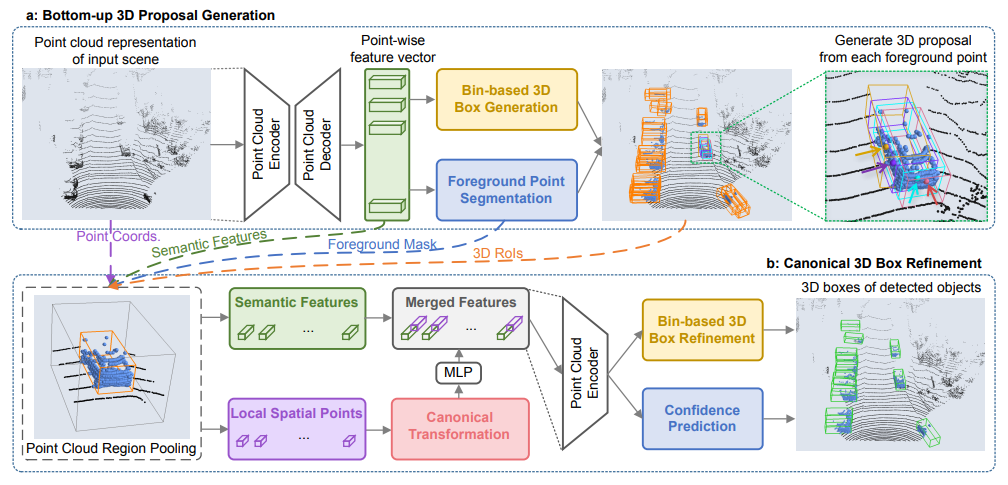
+Currently, there have been many kinds of voxel-based 3D single stage detectors, while point-based single stage methods are still underexplored. In this paper, we first present a lightweight and effective point-based 3D single stage object detector, named 3DSSD, achieving a good balance between accuracy and efficiency. In this paradigm, all upsampling layers and refinement stage, which are indispensable in all existing point-based methods, are abandoned to reduce the large computation cost. We novelly propose a fusion sampling strategy in downsampling process to make detection on less representative points feasible. A delicate box prediction network including a candidate generation layer, an anchor-free regression head with a 3D center-ness assignment strategy is designed to meet with our demand of accuracy and speed. Our paradigm is an elegant single stage anchor-free framework, showing great superiority to other existing methods. We evaluate 3DSSD on widely used KITTI dataset and more challenging nuScenes dataset. Our method outperforms all state-of-the-art voxel-based single stage methods by a large margin, and has comparable performance to two stage point-based methods as well, with inference speed more than 25 FPS, 2x faster than former state-of-the-art point-based methods.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+
+
+
+
+
+