■ DATABASE [COMP322] Kyungpook National University
- This course introduces the fundaemental concepts necessary for designing, using and implementing database systems and database applications. In this course, we learn the fundaementals of database modeling and design, the languages and models provided by the database management systems (DBMSes), and database system implementation techniques. The main goal of this course is to give you in-depth and up-to-date knowledge of of the most important aspects of database systems and applications. Specifically, the major topics of this course is as follows: (1) logical design (relational, semi-structural, NoSQL), (2) DBMS installation and plays, (3) SQL, (4) JDBC programming, (5) indexing, (6) transaction processing, (7) web server programming, and (8) up-to-date technologies including Big Data, MapReduce and Hadoop/Spark if time permits. Through strong lab practices and programming assignments, the students are expected to be more familiar with data management.
| Syllabus Image 001 | Syllabus Image 002 | Syllabus Image 003 |
|---|---|---|
 |
 |
 |
-
공용 데이터 (Shared Data) : 다양한 사용자들이 필요한 정보를 공동으로 이용할 목적으로 만들어진 자료이다.
-
운영 데이터 (Operational Data) : 한 조직체가 유지되고 운영되는데 필요한 모든 개체 데이터와 관계 데이터의 집합이다.
-
통합 데이터 (Integrated Data) : 데이터 집단에서 자료의 중복이나 군더더기를 제거하여 최적화시킨 데이터의 집합이다.
-
저장 데이터 (Stored Data) : 컴퓨터 시스템이 접근 가능한 저장 매체에 저당 된 데이터의 집합이다.
-
실시간 접근성 (Real-Time Accessibility) : 수시적이고 비정형적인 질의(query)에 대하여 실시간 처리로 응답할 수 있어야 한다.
-
지속적인 변화 (Continuous Evolution) : 새로운 데이터의 삽입(insertion), 기존 데이터의 삭제(deletion), 갱신(update)으로 항상 그 내용이 변하고, 또 그 속에서 현재의 정확한 데이터를 유지해야 한다.
-
동시 공유 (Concurrent Sharing) : 같은 내용의 데이터를 여러 사람이 서로 다른 방법으로 동시에 공용할 수 있어야 한다.
-
내용에 대한 참조 (Contents Reference) : 데이터베이스 내에 있는 데이터 레코드들은 주소나 위치에 의해서가 아니라 사용자가 요구하는 데이터의 내용에 따라 참조해야 한다.
| 👍 DATABASE Advantage | 👎 DATABASE Disadvantage |
|---|---|
| 데이터 중복 최소화 | 데이터베이스 전문가 필요 |
| 데이터공유 | 많은 비용 부담 |
| 일관성, 무결성, 보안성 유지 | 데이터 백업과 복구가 어려움 |
| 데이터의 논리적, 물리적 독리성 | 대용량 디스크로 엑서스가 집중되면 과부하 발생 |
| 데이터 저장 공간 절약 | 시스템의 복잡함 |
-
논리적 구조 : 사용자나 응용 프로그래머가 데이터베이스를 바라보는 관점에서 데이터 배치 형태를 의미하는 것으로 논리적 레코드를 가지고 사용자나 응용 프로그래머의 상상에 따라 전개한 모양을 의미한다.
-
물리적 구조 : 데이터가 물리적 저장 장치에 배치된 형태를 의미하는 것으로 저장 레코드를 이용하여 실제 물리적 저장 장치 위에 전개한 모양을 의미한다.
🔑 논리적 데이터 독립성 (Logical Data Independence) - 응용 프로그램과 데이터베이스를 독립시키는 것이다. 즉, 개념 스키마가 변경이 되더라도 외부 스키마가 영향을 받지 않는다.
-
Logical data is data about database, that is, it stores information about how data is managed inside. For example, a table (relation) stored in the database and all its constraints, applied on that relation.
-
Logical data independence is a kind of mechanism, which liberalizes itself from actual data stored on the disk. If we do some changes on table format, it should not change the data residing on the disk.
🔑 물리적 데이터 독립성 (Physical Data Independence) - 응용 프로그램 기억장치와 같은 물리적 장치를 독립시키는 것이다. 즉, 내부 스키마가 변경되더라도 개념 스키마가 영향을 받지 않는다.
-
All the schemas are logical, and the actual data is stored in bit format on the disk. Physical data independence is the power to change the physical data without impacting the schema or logical data.
-
For example, in case we want to change or upgrade the storage system itself − suppose we want to replace hard-disks with SSD − it should not have any impact on the logical data or schemas.
📣 데이터베이스 관리 시스템 (DBMS, DATABASE MANAGEMENT SYSTEM) - [네이버 지식백과] 데이터베이스 관리 시스템 (컴퓨터 개론, 2013. 3. 10., 김종훈, 김종진)
-
데이터베이스 관리 시스템(영어: database management system, DBMS)은 다수의 사용자들이 데이터베이스 내의 데이터를 접근할 수 있도록 해주는 소프트웨어 도구의 집합이다. DBMS은 사용자 또는 다른 프로그램의 요구를 처리하고 적절히 응답하여 데이터를 사용할 수 있도록 해준다.
-
데이터베이스를 직접 응용 프로그램들이 조작하는 것이 아니라 데이터베이스를 조작하는 별도의 소프트웨어가 있는데 이를 데이터베이스 관리 시스템(DBMS : DataBase Management System)이라 한다. 즉 데이터베이스 관리 시스템이란 데이터베이스를 관리하며 응용 프로그램들이 데이터베이스를 공유하며 사용할 수 있는 환경을 제공하는 소프트웨어다.
-
The database management system (DBMS) is the software that interacts with end users, applications, and the database itself to capture and analyze data. A general-purpose DBMS allows the definition, creation, querying, update, and administration of databases. A database is generally stored in a DBMS-specific format which is not portable, but different DBMSs can share data by using standards such as SQL and ODBC or JDBC. The sum total of the database, the DBMS and its associated applications can be referred to as a "database system". Often the term "database" is used to loosely refer to any of the DBMS, the database system or an application associated the database.
| 👉 DBMS Function Type | 👏 Explanation |
|---|---|
| 정의 | 데이터에 대한 형식, 구조, 제약조건들을 명세하는 기능이다. 이때 데이터베이스에 대한 정의 및 설명은 카탈로그나 사전의 형태로 저장된다. |
| 구축 | DBMS가 관리하는 기억 장치에 데이터를 저장하는 기능이다. |
| 조작 | 특정한 데이터를 검색하기 위한 질의, 데이터베이스의 갱신, 보고서 생성 기능 등을 포함한다. |
| 공유 | 여러 사용자와 프로그램이 데이터베이스에 동시에 접근하도록 하는 기능이다. |
| 보호 | 하드웨어나 소프트웨어의 오동작 또는 권한이 없는 악의적인 접근으로부터 시스템을 보호한다. |
| 유지보수 | 시간이 지남에 따라 변화하는 요구사항을 반영할 수 있도록 하는 기능이다. |
데이터 조작 언어(영어: Data Manipulation Language, DML)은 데이터베이스 사용자 또는 응용 프로그램 소프트웨어가 컴퓨터 데이터베이스에 대해 데이터 검색, 등록, 삭제, 갱신을 위한, 데이터베이스 언어 또는 데이터베이스 언어 요소이다.
/* MARK: - The SQL SELECT Statement */
SELECT column1, column2 FROM table_name;
/* MARK: - The SQL WHERE Clause */
SELECT column1, column2 FROM table_name WHERE condition;
/* MARK: - The SQL ORDER BY Keyword */
SELECT column1, column2 FROM table_name ORDER BY column1, column2 ASC|DESC;
/* MARK: - The SQL INSERT INTO Statement */
INSERT INTO table_name (column1, column2, column3) VALUES (value1, value2, value3);
/* MARK: - The SQL UPDATE Statement */
UPDATE table_name SET column1 = value1, column2 = value2 WHERE condition;
/* MARK: - The SQL DELETE Statement */
DELETE FROM table_name WHERE condition;데이터 정의 언어(영어: Data Definition Language, DDL)는 컴퓨터 사용자 또는 응용 프로그램 소프트웨어가 컴퓨터의 데이터를 정의하는 컴퓨터 언어 또는 컴퓨터 언어 요소이다.
/* MARK: - The SQL CREATE TABLE Statement */
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
column3 datatype,
);
/* MARK: -The SQL CREATE DATABASE Statement */
CREATE DATABASE databasename;
/* MARK: - The SQL DROP DATABASE Statement */
DROP DATABASE databasename;
/* MARK: - ALTER TABLE - ADD Column */
ALTER TABLE table_name ADD column_name datatype;
/* MARK: - ALTER TABLE - DROP COLUMN */
ALTER TABLE table_name DROP COLUMN column_name;
/* MARK: - ALTER TABLE - ALTER/MODIFY COLUMN */
ALTER TABLE table_name ALTER COLUMN column_name datatype;데이터 제어 언어(영어: Data Control Language, DCL)는 데이터베이스에서 데이터에 대한 액세스를 제어하기 위한 데이터베이스 언어 또는 데이터베이스 언어 요소이다. 권한 부여(GRANT)와 박탈(REVOKE)이 있으며, 설정할 수 있는 권한으로는 연결(CONNECT), 질의(SELECT), 자료 삽입(INSERT), 갱신(UPDATE), 삭제(DELETE) 등이 있다.
/* MARK: - The SQL Reovke DATABASE Statement */
REVOKE privilege_name ON object_name FROM {user_name |PUBLIC |role_name};
/* MARK: - The SQL Grant DATABASE Statement */
GRANT privilege_name ON object_name TO {user_name |PUBLIC |role_name} [WITH GRANT OPTION];-
현실 세계에 존재하는 데이터를 컴퓨터의 세계의 데이터베이스로 옮기는 변환 과정이다.
-
1️⃣ 개념적 데이터 모델링 (Conceptual Data Modeling): 현실 세계의 중요 데이터를 추출하여 개념 세계로 옮기는 작업이다.
-
2️⃣ 논리적 데이터 모델링 (Logical Data Modeling): 개념 세계의 데이터를 데이터베이스에 저장하는 구조로 표현하는 작업이다.
-
데이터 모델링의 결과물을 표현하는 도구이다.
-
1️⃣ 개념적 데이터 모델 (Coneptual Data Model): 현실 세계를 사람의 머리로 이해할 수 있도록 개념적 모델링의 결과물인 개념적 구조로 표현하는 도구다.
-
2️⃣ 논리적 데이터 모델 (Logical Data Model): 개념적 구조를 논리적 모델링하여 논리적 구조로 표현하는 도구이다.
-
An Entity Relationship Diagram (ERD) is a visual representation of different entities within a system and how they relate to each other.
-
They are widely used to design relational databases. The entities in the ER schema become tables, attributes and converted the database schema. Since they can be used to visualize database tables and their relationships it’s commonly used for database troubleshooting as well.
| ER Diagram Image | ER Diagram Name | ER Diagram explation |
|---|---|---|
 |
Entity | An entity can be a person, place, event, or object that is relevant to a given system. |
 |
Attribute | An attribute is a property, trait, or characteristic of an entity, relationship, or another attribute. |
 |
Relationship | A relationship describes how entities interact. |
- Ultimate ER Diagram Tutorial (Entity Relationship Diagrams)
- Entity-Relationship Diagram Symbols and Notation
-
시스템이 필요로 하는 데이터베이스, 테이블, 뷰, 인덱스, 접근 권한 등에 관한 정보를 메타 데이터 형태로 포함하는 시스템 데이터베이스이다. 사용자가 SQL 문을 실행시켜 기본 테이블, 뷰, 인덱스 등에 변화를 주면 시스템 카탈로그가 자동으로 테이블을 갱신한다. 카탈로그 자체도 시스템 테이블로 구성되어있어 일반 이용자도 SQL을 이용하여 내용을 검색해볼 수 있으나 카탈로그의 내용을 삽입, 삭제, 갱신할 수 없다. 잘못될 경우 치명적인 오류를 초래하므로 사용자의 직접적인 접근을 허용하지 않는다.
-
A system catalog is a group of tables and views that incorporate vital details regarding a database. Every database comprised of a system catalog and the information in the system catalog specifies the framework of the database. For instance, the data dictionary language (DDL) for every table in the database is saved in the system catalog.
📣 뷰 (View) - [네이버 지식백과] 뷰의 개념 (데이터베이스 개론, 2013. 6. 30., 김연희)
-
뷰(view)는 다른 테이블을 기반으로 만들어진 가상 테이블(virtual table)이다. 뷰를 가상 테이블이라고 하는 이유는 일반 테이블과 달리 데이터를 실제로 저장하고 있지 않기 때문이다. 물리적으로 존재하면서 실제로 데이터를 저장하는 일반 테이블과는 다르게 뷰는 논리적으로만 존재하면서도 일반 테이블과 동일한 방법으로 사용할 수 있어 사용자는 차이를 느끼기 어렵다.
-
In a database, a view is the result set of a stored query on the data, which the database users can query just as they would in a persistent database collection object. This pre-established query command is kept in the database dictionary. Unlike ordinary base tables in a relational database, a view does not form part of the physical schema: as a result set, it is a virtual table computed or collated dynamically from data in the database when access to that view is requested. Changes applied to the data in a relevant underlying table are reflected in the data shown in subsequent invocations of the view. In some NoSQL databases, views are the only way to query data.
-
Views can represent a subset of the data contained in a table. Consequently, a view can limit the degree of exposure of the underlying tables to the outer world: a given user may have permission to query the view, while denied access to the rest of the base table.
-
Views can join and simplify multiple tables into a single virtual table.
-
Views can act as aggregated tables, where the database engine aggregates data (sum, average, etc.) and presents the calculated results as part of the data.
-
Views can hide the complexity of data. For example, a view could appear as Sales2000 or Sales2001, transparently partitioning the actual underlying table.
-
Views take very little space to store; the database contains only the definition of a view, not a copy of all the data that it presents. Depending on the SQL engine used, views can provide extra security.
-
기본 테이블의 기본키를 구성하는 속성이 포함되어 있지 않은 뷰는 변경할 수 없다.
-
기본 테이블에 있던 내용이 아니라 집계 합수로 새로 계산된 내용을 포함하고 있는 뷰는 변경할 수 없다.
-
GROUP BY 절을 포함하여 정의한 뷰는 변경할 수 없다.
-
DISTINCT 키워드를 포함하여 정의한 뷰는 변경할 수 없다.
-
여러 개의 테이블을 조인하여 정의한 뷰는 변경할 수 없는 경우가 많다.
📣 트리거 (Database Trigger) - [네이버 지식백과] 트리거 [trigger] (두산백과)
-
데이터베이스 트리거(Database Trigger)는 테이블에 대한 이벤트에 반응해 자동으로 실행되는 작업을 의미한다. 트리거는 데이터 조작 언어(DML)의 데이터 상태의 관리를 자동화하는 데 사용된다. 트리거를 사용하여 데이터 작업 제한, 작업 기록, 변경 작업 감사 등을 할 수 있다.
-
데이터베이스 트리거는 트리거 테이블에 어떠한 변화(이벤트)가 일어나면 이에 따라 자동으로 실행되는 작업으로, 데이터의 상태를 자동을 관리하여 데이터베이스 상의 정보의 무결성(integrity)을 유지하는데 사용된다. 예를 들어 새로운 고객이 고객 테이블에 등록되는 경우 고객수와 관련된 총 고객수 값이 자동으로 증가되도록 트리거를 정의할 수 있다.
-
A database trigger is procedural code that is automatically executed in response to certain events on a particular table or view in a database. The trigger is mostly used for maintaining the integrity of the information on the database. For example, when a new record (representing a new worker) is added to the employees table, new records should also be created in the tables of the taxes, vacations and salaries. Triggers can also be used to log historical data, for example to keep track of employees' previous salaries.
-
데이터베이스 스키마(database schema)는 데이터베이스에서 자료의 구조, 자료의 표현 방법, 자료 간의 관계를 형식 언어로 정의한 구조이다. 데이터베이스 관리 시스템(DBMS)이 주어진 설정에 따라 데이터베이스 스키마를 생성하며, 데이터베이스 사용자가 자료를 저장, 조회, 삭제, 변경할 때 DBMS는 자신이 생성한 데이터베이스 스키마를 참조하여 명령을 수행한다.
-
외부 스키마(External Schema) : 프로그래머나 사용자의 입장에서 데이터베이스의 모습으로 조직의 일부분을 정의한 것이다.
-
개념 스키마(Conceptual Schema) : 모든 응용 시스템과 사용자들이 필요로하는 데이터를 통합한 조직 전체의 데이터베이스 구조를 논리적으로 정의한 것이다.
-
내부 스키마(Internal Schema) : 전체 데이터베이스의 물리적 저장 형태를 기술하는 것이다.
-
트랜잭션은 하나의 논리적 단위를 구성하는 데이터베이스 연산의 모임이다. 동시에 여러 트랜잭션이 수행되기 위해서 데이터베이스의 일관성이 보장되어야 하며 이를 위해 동시성 제어(concurrency control)와 회복 제어(recovery control)를 위한 모듈이 있으며 이 둘을 합쳐 트랜잭션 관리 모듈(transaction management module)이라고 한다. 데이터베이스 시스템은 각각의 트랜잭션에 대해 원자성(Atomicity), 일관성(Consistency), 독립성(Isolation), 영구성(Durability) 을 보장한다.
-
동시성제어 모듈(concurreny control module) : 데이터베이스를 일관성 있게 유지하기 위하여 동시에 수행되는 트랜잭션들 사이의 상호작용을 제어한다.
-
회복제어 모듈(recovery control module) : 데이터베이스를 일관성 있게 유지하기 위하여 업데이트를 하는 동안 시스템 장애에도 데이터베이스의 기존 상태가 유지된다.
⚡ 트랜젝션 ACID (Database Transation ACID) - [네이버 지식백과] 트랜잭션의 특성 (데이터베이스 개론, 2013. 6. 30., 한빛아카데미(주))
ACID(원자성, 일관성, 독립성, 지속성)는 데이터베이스 트랜잭션이 안전하게 수행된다는 것을 보장하기 위한 성질을 가리키는 약어이다.
-
원자성(Atomicity) : 트랜잭션과 관련된 작업들이 부분적으로 실행되다가 중단되지 않는 것을 보장하는 능력이다. 예를 들어, 자금 이체는 성공할 수도 실패할 수도 있지만 보내는 쪽에서 돈을 빼 오는 작업만 성공하고 받는 쪽에 돈을 넣는 작업을 실패해서는 안된다. 원자성은 이와 같이 중간 단계까지 실행되고 실패하는 일이 없도록 하는 것이다.
-
일관성(Consistency) : 트랜잭션이 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 유지하는 것을 의미한다. 무결성 제약이 모든 계좌는 잔고가 있어야 한다면 이를 위반하는 트랜잭션은 중단된다.
-
독립성(Isolation) : 트랜잭션을 수행 시 다른 트랜잭션의 연산 작업이 끼어들지 못하도록 보장하는 것을 의미한다. 이것은 트랜잭션 밖에 있는 어떤 연산도 중간 단계의 데이터를 볼 수 없음을 의미한다. 은행 관리자는 이체 작업을 하는 도중에 쿼리를 실행하더라도 특정 계좌간 이체하는 양 쪽을 볼 수 없다. 공식적으로 독립성은 트랜잭션 실행내역은 연속적이어야 함을 의미한다. 성능관련 이유로 인해 이 특성은 가장 유연성 있는 제약 조건이다. 자세한 내용은 관련 문서를 참조해야 한다.
-
지속성(Durability) : 성공적으로 수행된 트랜잭션은 영원히 반영되어야 함을 의미한다. 시스템 문제, DB 일관성 체크 등을 하더라도 유지되어야 함을 의미한다. 전형적으로 모든 트랜잭션은 로그로 남고 시스템 장애 발생 전 상태로 되돌릴 수 있다. 트랜잭션은 로그에 모든 것이 저장된 후에만 commit 상태로 간주될 수 있다.
⚡ 트랜잭션의 상태 (Transcation State) - [네이버 지식백과] 트랜잭션의 상태 (데이터베이스 개론, 2013. 6. 30., 한빛아카데미(주))
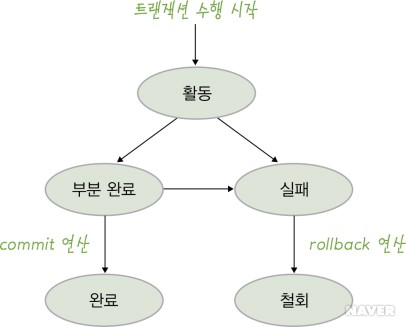
- 트랜잭션이 수행을 시작하면 활동 상태가 되고, 활동 상태의 트랜잭션이 마지막 연산을 처리하고 나면 부분 완료 상태, 부분 완료 상태의 트랜잭션이 commit 연산을 실행하면 완료 상태가 된다. 활동 상태나 부분 완료 상태에서 여러 원인들로 인해 더는 정상적인 수행이 불가능하게 되면 트랜잭션은 실패 상태가 된다. 실패 상태의 트랜잭션은 rollback 연산의 실행으로 철회 상태가 된다. 트랜잭션이 완료 상태이거나 철회 상태가 되면 트랜잭션이 종료된 것으로 판단한다.
- 트랜잭션이 수행을 시작하여 현재 수행 중인 상태를 활동(active) 상태라고 한다. 활동 상태인 트랜잭션은 상황에 따라 부분 완료 상태나 실패 상태가 된다.
- 트랜잭션의 마지막 연산이 실행된 직후의 상태를 부분 완료(partially committed) 상태라 하는데, 이는 트랜잭션의 모든 연산을 처리한 상태다. 부분 완료 상태인 트랜잭션은 모든 연산의 처리가 끝났지만 트랜잭션이 수행한 최종 결과를 데이터베이스에 아직 반영하지 않은 상태이므로, 아직은 트랜잭션의 수행이 성공적으로 완료됐다고 볼 수 없다. 부분 완료 상태의 트랜잭션은 상황에 따라 완료 상태나 실패 상태가 될 수 있다.
- 트랜잭션이 성공적으로 완료되어 commit 연산을 실행한 상태를 완료(committed) 상태라고 한다. 트랜잭션이 완료 상태가 되면 트랜잭션이 수행한 최종 결과를 데이터베이스에 반영하고, 데이터베이스가 새로운 일관된 상태가 되면서 트랜잭션이 종료된다.
- 하드웨어, 소프트웨어의 문제나, 트랜잭션 내부의 오류 등의 이유로 장애가 발생하여 트랜잭션의 수행이 중단된 상태를 실패(failed) 상태라고 한다. 트랜잭션이 더는 정상적으로 수행을 계속할 수 없을 때 실패 상태가 된다.
- 트랜잭션의 수행이 실패하여 rollback 연산을 실행한 상태를 철회(aborted) 상태라고 한다. 트랜잭션이 철회 상태가 되면 지금까지 실행한 트랜잭션의 연산을 모두 취소하고 트랜잭션이 수행되기 전의 데이터베이스 상태로 되돌리면서 트랜잭션이 종료된다. 철회 상태로 종료된 트랜잭션은 상황에 따라 다시 수행되거나 폐기된다. 트랜잭션의 내부 문제가 아닌, 하드웨어의 이상이나 소프트웨어의 오류로 트랜잭션의 수행이 중단되고 철회 상태가 된 경우에는 철회된 트랜잭션을 다시 시작한다. 하지만 트랜잭션이 처리하려는 데이터가 데이터베이스에 존재하지 않거나 트랜잭션의 논리적인 오류가 원인인 경우에는 철회된 트랜잭션을 폐기한다.
★ 데이터베이스 이상현상 (Database Anomaly) - 데이터베이스 개론, 2013. 6. 30., 한빛아카데미(주)
- 데이터베이스를 잘못 설계하면 불필요한 데이터 중복이 발생하여 릴레이션에 대한 데이터의 삽입·수정·삭제 연산을 수행할 때 부작용들이 발생할 수 있다. 이러한 부작용을 이상(anomaly) 현상이라 한다.
| 🐱 Insert Anomaly | 🐱 Delete Anomaly | 🐱 Update Anomaly |
|---|---|---|
 |
 |
 |
-
릴레이션에 새 데이터를 삽입하기 위해 원치 않는 불필요한 데이터도 함께 삽입해야 하는 문제를 삽입 이상(insertion anomaly)이라 한다.
-
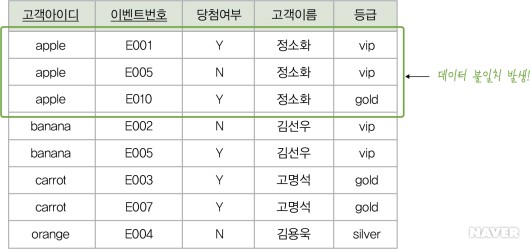
예를 들어 아이디가 melon이고, 이름이 성원용, 등급이 gold인 신규 고객이 회원으로 가입하여, 이상 현상의 종류의 [이상 현상 설명을 위한 릴레이션의 예]의 이벤트참여 릴레이션에 이 고객에 대한 데이터를 삽입해야 한다고 해보자. 이 고객이 참여한 이벤트가 아직 없다면 이벤트참여 릴레이션에 이 고객에 대한 데이터를 삽입할 수 없다. 이벤트참여 릴레이션의 기본키가 고객아이디와 이벤트번호 속성이고, 기본키를 구성하는 속성은 널 값을 가질 수 없다는 제약이 존재하기 때문이다. 즉, 고객아이디와 참여한 이벤트번호가 모두 존재해야 이벤트참여 릴레이션에 새 고객의 데이터를 삽입할 수 있다. 따라서 성원용 고객에 대한 데이터를 이벤트참여 릴레이션에 삽입하려면 실제로 참여하지 않은 임시 이벤트번호를 삽입해야 하므로 이벤트참여 릴레이션에는 삽입 이상이 발생하게 된다.
-
릴레이션에서 투플을 삭제하면 꼭 필요한 데이터까지 함께 삭제하여 데이터가 손실되는 연쇄 삭제 현상을 삭제 이상(delete anomaly)이라 한다.
-
아이디가 orange인 고객이 이벤트 참여를 취소하여 이상 현상의 종류의 [이상 현상 설명을 위한 릴레이션의 예]의 이벤트참여 릴레이션에서 관련된 투플을 삭제해야 한다면, [그림 9-3]과 같이 하나의 투플만 삭제하면 된다. 그런데 이 투플은 아이디가 orange인 고객이 참여하고 있는 이벤트에 대한 정보만 가지고 있는 것이 아니라 해당 고객에 대한 정보인 고객아이디·고객이름·등급에 대한 정보도 유일하게 가지고 있다. 따라서 이 투플이 삭제되면 이벤트 참여와 관련이 없음에도 불구하고 해당 고객에 대한 고객아이디·고객이름·등급 데이터까지 원치 않게 손실되는 삭제 이상이 발생하게 된다.
-
릴레이션의 중복된 투플들 중 일부만 수정하여 데이터가 불일치하게 되는 모순이 발생하는 것을 갱신 이상(update anomaly)이라 한다.
-
이상 현상의 종류의 [이상 현상 설명을 위한 릴레이션의 예]의 이벤트참여 릴레이션에는 아이디가 apple인 고객에 대한 투플이 세 개 존재하여, 고객아이디·고객이름·등급 속성의 값이 중복되어 있다. 아이디가 apple인 고객의 등급이 gold에서 vip로 변경된다면, 이벤트참여 릴레이션에서 apple 고객에 대한 투플 세 개의 등급 속성 값이 모두 수정되어야 한다. 그렇지 않고 [그림 9-2]와 같이 두 개의 투플만 등급이 수정되면 apple 고객이 서로 다른 등급을 가지는 모순이 생겨 갱신 이상이 발생하게 된다.
📣 정규화 (Nomalization) - [네이버 지식백과] 정규화 (데이터베이스 개론, 2013. 6. 30., 한빛아카데미(주))
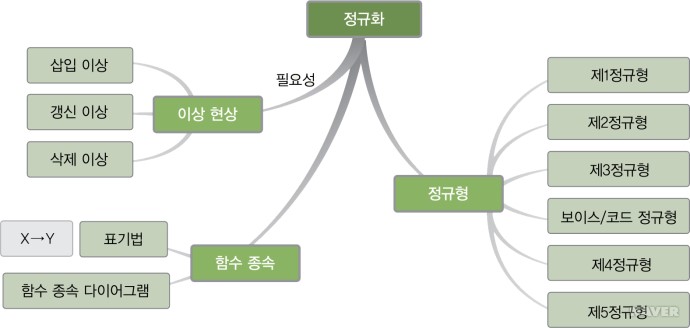
- 함수 종속성을 이용하여, 릴레이션을 연관성이 있는 속성들로만 구성되도록 분해하여 이상 현상이 발생하지 않는 바람직한 릴레이션으로 만들어 나가는 과정이다. 또는 이상 현상을 제거하면서 데이터베이스를 올바르게 설계해 나가는 과정이라고도 한다.

-
관계형 데이터베이스(關係形 Database, Relational Database, 문화어: 관계자료기지, 관계형자료기지, RDB)는 키(key)와 값(value)들의 간단한 관계를 테이블화 시킨 매우 간단한 원칙의 전산정보 데이터베이스이다.
-
관계형 데이터베이스는 데이터 항목 간에 사전 정의된 관계가 있을 때 그러한 데이터 항목들의 모음을 가리킵니다. 이들 항목은 열과 행으로 이루어진 테이블 집합으로 구성됩니다. 테이블은 데이터베이스에 표시할 해당 객체들에 관한 정보를 수록하는 데 사용됩니다. 테이블의 각 열은 특정 종류의 데이터를 수록하며 필드는 속성의 실제 값을 저장합니다. 테이블의 행은 한 객체 또는 엔터티와 관련된 값들의 모음을 나타냅니다. 테이블의 각 행은 기본 키라고 부르는 고유 식별자로 표시할 수 있고 여러 테이블에 있는 행들은 외래 키를 사용하여 상호 연결될 수 있습니다. 이 데이터는 데이터베이스 테이블 자체를 재구성하지 않고도 여러 가지 방법으로 액세스할 수 있습니다.
-
튜플을 유일하게 구별하기 위해 모든 속성을 이용하는 것보다 일부 속성만 이용하는 것이 효율성을 높일 수 있다. 릴레이션에 포함된 튜플들을 유일하게 구별해주는 역할은 속성 또는 속성들의 집합인 키가 담당한다. 키(key)는 관계 데이터 모델에서 중요한 제약조건을 정의한다. 또한 튜플을 처리하는 데 중요한 역할을 하므로 키의 개념을 정확히 이해할 필요가 있다.
-
관계 데이터 모델에서는 키를 다음과 같이 수퍼키, 후보키, 기본키, 대체키, 외래키의 5가지로 분류할 수 있다.
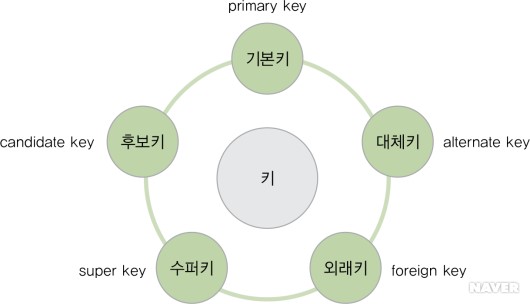
- 슈퍼키(super key)는 유일성의 특성을 만족하는 속성 또는 속성들의 집합이다. 유일성(uniqueness)은 키가 갖추어야 하는 기본 특성으로, 하나의 릴레이션에서 키로 지정된 속성의 값은 튜플마다 달라야 한다는 의미다. 즉, 키 값이 같은 투플은 존재할 수 없다.
-
관계형 데이터베이스에서 한 테이블 속성 집합이 다른 테이블의 기본키가 되는 것을 말한다.
-
하나 이상의 테이블을 연결하여 사용하는 관계형 데이터베이스에서 하나의 테이블 속성 또는 속성 집합이 다른 테이블의 기본키가 되는 것을 의미하며, 데이터베이스에 존재하는 테이블의 관계에서 참조 무결성을 보장하기 위해 사용된다. 여기서 기본키는 테이블에 저장되어 있는 각각의 데이터를 구분하는 키를 의미한다. 기본키는 유일해야만 하고, 중복되는 값과 비어있는 값(Null 값)이 없어야만 한다. 반면 외래키는 중복되는 값을 가질 수 있으며 비어있는 값(Null 값) 또한 가질 수 있다.
릴레이션에서 투플을 구별하기 위해 여러 개의 후보키를 모두 사용할 필요는 없다. 데이터베이스 설계자나 관리자는 여러 후보키 중에서 기본적으로 사용할 키를 반드시 선택해야 하는데 이것이 기본키(primary key)다. 만약 후보키가 한 개만 존재하면 당연히 해당 후보키를 기본키로 선택해야 하겠지만 여러 개일 경우에는 데이터베이스 사용 환경을 고려하여 적합한 것을 기본키로 선택하면 된다.
- 널 값을 가질 수 있는 속성이 포함된 후보키는 기본키로 부적합하다.
기본키는 투플을 식별할 뿐만 아니라 릴레이션에서 원하는 투플을 찾기 위한 기본 접근 방법을 제공하는 중요한 역할을 한다. 그러므로 기본키가 널 값인 투플은 다른 투플들과 구별하여 접근하기 어려우므로 이런 가능성이 있는 키는 기본키로 선택하지 않는 것이 좋다.
- 값이 자주 변경될 수 있는 속성이 포함된 후보키는 기본키로 부적합하다.
기본키는 다른 투플과 구별되는 값을 가지고 널 값은 허용하지 않으므로 이를 확인하는 작업이 필요하다. 그런데 값이 자주 변경되는 속성으로 구성된 후보키를 기본키로 선택하면 속성 값이 바뀔 때마다 기본키 값으로 적합한지 여부를 판단해야 하므로 번거롭다. 그러므로 값이 자주 변경되지 않는 속성으로 구성된 후보키를 기본키로 선택하는 것이 좋다.
- 단순한 후보키를 기본키로 선택한다.
단순한 후보키는 자리수가 적은 정수나 단순 문자열인 속성으로 구성되거나, 구성하는 속성의 개수가 적은 후보키다. 데이터베이스를 이용하는 일반 사용자뿐만 아니라 데이터베이스를 실제로 처리하는 컴퓨터 시스템도 단순 값 처리를 선호한다.
-
후보키(candidate key)는 유일성과 최소성을 만족하는 속성 또는 속성들의 집합이다. 최소성(minimality)은 키를 구성하고 있는 여러 속성 중에서 하나라도 없으면 투플을 유일하게 구별할 수 없는, 꼭 필요한 최소한의 속성들로만 키를 구성하는 특성이다. 그러므로 하나의 속성으로 구성된 키는 당연히 최소성을 만족한다.
-
후보키가 되기 위해 만족해야 하는 유일성과 최소성의 특성은 새로운 투플이 삽입되거나 기존 튜플의 속성 값이 바뀌어도 유지되어야 한다. 그리고 후보키를 선정할 때는 현재의 릴레이션 내용, 즉 릴레이션 인스턴스만 보고 유일성과 최소성을 판단해서는 안 된다. 데이터베이스가 사용될 현실 세계의 환경까지 염두에 두고 속성의 본래 의미를 정확히 이해한 후 수퍼키와 후보키를 선별해야 한다.

-
대체키(alternate key)는 기본키로 선택되지 못한 후보키들이다. 이름에서 알 수 있듯이 대체키는 기본키를 대신할 수 있지만 기본키가 되지 못하고 탈락한 이유가 있을 수 있다.
-
데이터베이스에서 복수의 후보 키가 있는 경우에 설계자는 그중의 하나를 1차 키(primary key)로 지정해야 하는데, 이때 1차 키로 지정되지 않은 키를 이르는 말.
-
관계형 데이터베이스에서 데이터의 정확성과 일관성을 유지하고, 데이터에 결손과 부정합이 없음을 보증하는 것을 의미한다.
-
데이터 무결성이란 데이터베이스 내의 데이터에 대한 정확성, 일관성, 유효성, 신뢰성을 보장하기 위해 데이터 변경 혹은 수정 시 여러가지 제한을 두어 데이터의 정확성을 보증하는 것을 말한다.
-
데이터베이스 무결성을 보장하기 위해서는 데이터를 조작하는 프로그램 즉, 응용 내에 무결성 조건 검증 코드를 추가하는 방법, 트리거 이벤트를 통해 무결성 조건을 유지하는 방법, 혹은 데이터베이스 내의 제약 조건 설정을 통해 무결성을 유지하는 방법과 같이 크게 세 가지 방법이 있다.
-
엔터티 무결성(entity integrity) : 엔터티 무결성은 행을 특정 테이블의 고유 엔터티로 정의하는 것으로 해당 열에 중복된 값을 허가하지 않는 UNIQUE 제약 조건 또는 PRIMARY KEY 제약 조건을 설정하여 테이블의 기본 키나 식별자로 사용되는 열의 무결성을 강제하도록 한다.
-
도메인 무결성(domain integrity) : 열에 대한 데이터 무결성을 보장하기 위한 것으로 컬럼의 값이 널 값을 허용하지 않거나, 데이터 타입이 적절한지, 올바른 형식의 데이터가 저장되었는지 등을 확인하는 것이다. 체크(CHECK), 디폴트(DEFAULT) , NOT NULL 등의 제약(constraints)들로 이러한 도메인 무결성을 보장할 수 있다. 예를 들어, 생일 날짜 컬럼에 알파벳이 입력되는 경우 도메인 무결성을 위반하는 것이라 볼 수 있다.
-
참조 무결성(referential integrity) : 개체 간 참조 관계가 존재할 때, 두 개체 간 데이터가 일관성을 가질 수 있도록 보증하는 방법이다. 일반적으로 외부키(Foreign Key)로 제약을 주어 무결성을 보장할 수 있고 데이터 변경이 있을 때(데이터 행 입력 혹은 삭제 시) 데이터 입력 및 수정 시 묵시적으로 수행되는 프로시저(procedure)인 트리거(trigger)를 통해 관련 값들을 재조정할 수 있다.
-
사용자 정의 무결성(user-defined integrity) : 위의 세 가지 무결성에 해당하지 않지만, 사용자가 정의한 규칙에 의한 무결성으로 다양한 응용의 필요에 따라 정의한다.

- 네트워크상의 여러 이용자가 실시간으로 데이터베이스의 데이터를 갱신하거나 조회하는 등의 단위 작업을 처리하는 방식을 말한다. 주로 신용카드 조회업무나 자동 현금 지급 등 금융 전산 관련 부문에서 많이 발생하기 때문에 ‘온라인 거래처리’라고도 한다. 이 방식의 특징은 기존 컴퓨터 통신에서 이용해 온 온라인 방식과 달리 다수의 이용자가 거의 동시에 이용할 수 있도록 송수신 자료를 트랜잭션(데이터 파일의 내용에 영향을 미치는 거래 ·입출고 ·저장 등의 단위 행위) 단위로 압축, 비어 있는 공간을 다른 사용자들이 함께 쓸 수 있도록 한 점이다.
- 데이터베이스와 객체 지향 프로그래밍 언어 간의 호환되지 않는 데이터를 변환하는 프로그래밍 기법이다. 객체 관계 매핑 라고도 부른다. 객체 지향 언어에서 사용할 수 있는 "가상" 객체 데이터베이스를 구축하는 방법이다.
- NoSQL 데이터베이스는 단순 검색 및 추가 작업을 위한 매우 최적화된 키 값 저장 공간으로, 레이턴시와 스루풋과 관련하여 상당한 성능 이익을 내는 것이 목적이다. NoSQL 데이터베이스는 빅데이터와 실시간 웹 애플리케이션의 상업적 이용에 널리 쓰인다. 또, NoSQL 시스템은 SQL 계열 쿼리 언어를 사용할 수 있다는 사실을 강조한다는 면에서 "Not only SQL"로 불리기도 한다.

- NoSQL 데이터베이스는 특정 데이터 모델에 대해 특정 목적에 맞추어 구축되는 데이터베이스로서 현대적인 애플리케이션 구축을 위한 유연한 스키마를 갖추고 있습니다. NoSQL 데이터베이스는 개발의 용이성, 기능성 및 확장성을 널리 인정받고 있습니다. 문서, 그래프, 키 값, 인 메모리, 검색을 포함해 다양한 데이터 모델을 사용합니다.

- 일관성(Consistency): 모든 노드가 같은 순간에 같은 데이터를 볼 수 있다.
- 가용성(Availability): 모든 요청이 성공 또는 실패 결과를 반환할 수 있다.
- 분할내성(Partition tolerance): 메시지 전달이 실패하거나 시스템 일부가 망가져도 시스템이 계속 동작할 수 있다.
NoSQL은 AP 또는 CP의 특징을 만족한다. 데이터의 신뢰성보다는 분산에 중점을 둔 방식이므로 약간의 데이터의 유실, 변형 등이 발생하는 것을 감안한다. 하지만 빠르게 확장하여 대규모 데이터를 저장하고 핸들링 할 수 있는 구조를 갖출 수 있도록 한다.
NoSQL 데이터베이스는 탁월한 사용자 경험을 제공하기 위하여 유연성과 확장성을 비롯해 고성능의 매우 기능적인 데이터베이스를 필요로 하는 모바일, 웹이나 게이밍과 같은 다양한 현대적인 애플리케이션에 적합합니다.
- 관계형 모델을 사용하지 않으며 테이블간의 조인 기능 없음
- 직접 프로그래밍을 하는 등의 비SQL 인터페이스를 통한 데이터 액세스
- 대부분 여러 대의 데이터베이스 서버를 묶어서(클러스터링) 하나의 데이터베이스를 구성
- 관계형 데이터베이스에서는 지원하는 Data처리 완결성(Transaction ACID 지원) 미보장
- 데이터의 스키마와 속성들을 다양하게 수용 및 동적 정의 (Schema-less)
- 데이터베이스의 중단 없는 서비스와 자동 복구 기능지원
- 다수가 Open Source로 제공
- 확장성, 가용성, 높은 성능
-
유연성: NoSQL 데이터베이스는 일반적으로 유연한 스키마를 제공하여 보다 빠르고 반복적인 개발을 가능하게 해줍니다. 이같은 유연한 데이터 모델은 NoSQL 데이터베이스를 반정형 및 비정형 데이터에 이상적으로 만들어 줍니다.
-
확장성: NoSQL 데이터베이스는 일반적으로 고가의 강력한 서버를 추가하는 대신 분산형 하드웨어 클러스터를 이용해 확장하도록 설계되었습니다. 일부 클라우드 제공자들은 완전관리형 서비스로서 이런 운영 작업을 보이지 않게 처리합니다.
-
고성능: NoSQL 데이터베이스는 특정 데이터 모델(문서, 키 값, 그래프 등) 및 액세스 패턴에 대해 최적화되어 관계형 데이터베이스를 통해 유사한 기능을 충족하려 할 때보다 뛰어난 성능을 얻게 해줍니다.
-
고기능성: NoSQL 데이터베이스는 각 데이터 모델에 맞추어 특별히 구축된 뛰어난 기능의 API와 데이터 유형을 제공합니다.
-
Key-value stores are the simplest NoSQL databases. Every single item in the database is stored as an attribute name, or key, together with its value. Examples of key-value stores are Riak and Voldemort. Some key-value stores, such as Redis, allow each value to have a type, such as "integer", which adds functionality.
-
Document databases pair each key with a complex data structure known as a document. Documents can contain many different key-value pairs, or key-array pairs, or even nested documents.
-
Wide-column stores such as Cassandra and HBase are optimized for queries over large datasets, and store columns of data together, instead of rows.
-
Graph stores are used to store information about networks, such as social connections. Graph stores include Neo4J and HyperGraphDB.
-
Key Value DB : Key와 Value의 쌍으로 데이터가 저장되는 가장 단순한 형태의 솔루션으로 Amazon의 Dynamo Paper에서 유래되었습니다. Riak, Vodemort, Tokyo 등의 제품이 많이 알려져 있습니다.
-
Wide Columnar Store : Big Table DB라고도 하며, Google의 BigTable Paper에서 유래되었습니다. Key Value 에서 발전된 형태의 Column Family 데이터 모델을 사용하고 있고, HBase, Cassandra, ScyllaDB 등이 이에 해당합니다.
-
Document DB : Lotus Notes에서 유래되었으며, JSON, XML과 같은 Collection 데이터 모델 구조를 채택하고 있습니다. MongoDB, CoughDB가 이 종류에 해당합니다.
-
Graph DB : Euler & Graph Theory에서 유래한 DB입니다. Nodes, Relationship, Key-Value 데이터 모델을 채용하고 있습니다. Neo4J, OreientDB 등의 제품이 있습니다.
- 빅 데이터(영어: big data)란 기존 데이터베이스 관리도구의 능력을 넘어서는 대량(수십 테라바이트)의 정형 또는 심지어 데이터베이스 형태가 아닌 비정형의 데이터 집합조차 포함한 데이터로부터 가치를 추출하고 결과를 분석하는 기술이다.
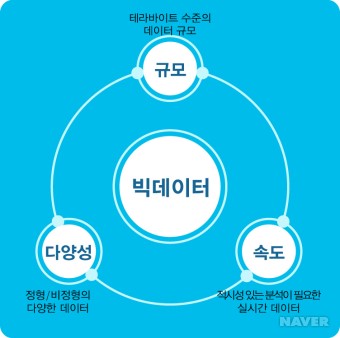
- 빅데이터의 공통적 특징은 3V로 설명할 수 있다. 3V는 데이터의 크기(Volume), 데이터의 속도(Velocity), 데이터의 다양성(variety)을 나타내며 이러한 세 가지 요소의 측면에서 빅데이터는 기존의 데이터베이스와 차별화된다. 데이터 크기(Volume)는 단순 저장되는 물리적 데이터양을 나타내며 빅데이터의 가장 기본적인 특징이다. 데이터 속도(Velocity)는 데이터의 고도화된 실시간 처리를 뜻한다. 이는 데이터가 생성되고, 저장되며, 시각화되는 과정이 얼마나 빠르게 이뤄져야 하는지에 대한 중요성을 나타낸다. 다양성(Variety)은 다양한 형태의 데이터를 포함하는 것을 뜻한다. 정형 데이터뿐만 아니라 사진, 오디오, 비디오, 소셜 미디어 데이터, 로그 파일 등과 같은 비정형 데이터도 포함된다.
- 버퍼란 어떤 장치에서 다른 장치로 데이터를 송신할 때 일어나는 시간의 차이나 데이터 흐름의 속도 차이를 조정하기 위해 일시적으로 데이터를 기억시키는 장치이다.
- 채널이 데이터를 버퍼에 저장하면 프로세서가 처리하는 방식으로 진행된다. 이경우 채널이 데이터를 저장하는 동안에는 데이터에 대한 처리가 이루어질 수 없으며, 프로세서가 데이터를 처리하는 동안에는 다른 데이터가 저장될 수 없게된다.
- 데이터에 대한 저장과 처리가 동시에 일어날 수 있다. 입력채널이 첫 번째 버퍼에 데이터를 저장하는 동안 프로세서가 두 번째 버퍼의 데이터를 처리할 수 있는 것이다. 이렇게 두개의 버퍼를 서로 교대로 사용하는 것을 플립플롭버퍼링(flip-flop buffering)이라하고, 여러개의 버퍼를 번갈아 사용하는 것을 순환버퍼링(circular buffering)이라고 한다.
-
여러 개의 하드 디스크에 일부 중복된 데이터를 나눠서 저장하는 기술이다. 디스크 어레이(disk array)라고도 한다. 데이터를 나누는 다양한 방법이 존재하며, 이 방법들을 레벨이라 하는데, 레벨에 따라 저장장치의 신뢰성을 높이거나 전체적인 성능을 향상시키는 등의 다양한 목적을 만족시킬 수 있다.
-
RAID는 여러 개의 디스크를 하나로 묶어 하나의 논리적 디스크로 작동하게 하는데, 하드웨어적인 방법과 소프트웨어적인 방법이 있다. 하드웨어적인 방법은 운영 체제에 이 디스크가 하나의 디스크처럼 보이게 한다. 소프트웨어적인 방법은 주로 운영체제 안에서 구현되며, 사용자에게 디스크를 하나의 디스크처럼 보이게 한다.
| RAID 0 | RAID 1 | RAID 2 | RAID 3 | RAID 4 |
|---|---|---|---|---|
 |
 |
 |
 |
 |
-
RAID 0: 빠른 데이터 입출력을 위해 데이터 스트라이핑을 제공한다.
-
RAID 1: 데이터의 안정성을 위하여 미러링을 제공한다. 가용 용량은 절반으로 줄어든다.
-
RAID 2: ECC 기능이 없는 드라이브를 위해 해밍오류 정정 코드를 사용한다.
-
RAID 3: 패리티 정보를 위한 전용 디스크를 사용하고, 나머지 디스크 드라이브에 바이트 단위로 데이터를 균등하게 분산 저장한다.
-
RAID 4: 모든 데이터를 블록 단위로 분산처리한다. 이때 모든 블록들은 각 디스크에 균등하게 저장되진 않는다.
| 🚀 Github QR Code | 📝 Naver-Blog QR Code | 👓 Linked-In QR Code |
|---|---|---|
 |
 |
 |