Workflow EN
[ Home ][ Workflow ][ Workflow EN ][ Twgit ][ Twgit EN ]
1. Introduction
2. Links
3. Proposed Workflow
3.1. New Process
3.2. CI errors
3.3. Release errors
3.4. Unviable release
3.5. Feature developped but given up
3.6. Dependency between features in development
3.7. Hotfix
3.8. Subprojects
3.9. Trivial Ticket
3.10. Transition
4. Another possible workflow
This workflow specificities are:
- to have a "stable" branch, with all the qualified/validated versions of the code
- to allow to choose the features (development branches) being part of the next release to be delivered - and to change your mind in case of integration problems for instance.
- to start each new branch from the last stable point to ensure the developers they have the most possible bug-free working codebase
- to allow continuous integration from the start
- to keep everything as simple as possible
- to add to bash a git layer to semi-automate git operations, with as many checks as possible, and while displaying relevant information
We want to have a real stable branch (in black on the diagram below). The idea behind being that only the tested and approved releases (in blue on the diagram) be merged into it.
In this new process, each feature (Redmine ticket or subproject, cf. sections Subprojects and Trivial Ticket) always requires creating a dedicated branch (feature-1 and feature-2 in orange on the diagram), that branch always being created from the last stable node. But once the tickets solved, the corresponding branches are always merged into the Continuous Integration branch (CI, in green on the diagram, step a and b).
Unitary tests can this way ensure the features quality and compatibility.
All this aiming at identifying most of the problems before the start of a new release, thus saving precious time.
After merge on the CI branch, features selected to be in the new release are merged into (step c on the diagram).
Once the release qualified, it is tagged and merged into the stable branch (step d on the diagram).
The workflow is ready for the next iteration!
Cases studied hereafter aim at finding solutions to everyday life problems.

 It is critical to keep the
It is critical to keep the CI branch as close as possible to the stable, so that unitary tests actually mean something (as far as the next releases are concerned).
CI can be seen as the release with all the features.
Case studies below take this into consideration, and in practice, only the case Feature developped but given up reflects this constraint.
 In this process, the CI branch is optionnal : it is not mandatory for the process and can be setup afterwards...
Its goal is the detection of errors before the creation of a new release, but
in any case, the releases and stable branch are under continuous integration.
In this process, the CI branch is optionnal : it is not mandatory for the process and can be setup afterwards...
Its goal is the detection of errors before the creation of a new release, but
in any case, the releases and stable branch are under continuous integration.
A feature is created from the last stable node (step a on the diagram).
Once developped, it is merged inot the CI branch (step b).
How to react if after the commit an error is detected by the continuous integration process?
The solution consists in resuming the developement of the faulty feature(s) (step c), then merging again into CI (step d).
If there's no error anymore and the feature is selected for the next release, then you can merge it into the given branch (step e).

Some features are developped and merged into the CI branch (step a on the diagram).
As no error was detected, the features selected for the new release are merged into this one (step b).
How to react if a bug or an integration problem is found on this release ?
Two possible cases:
- If the problems are due to one or some specific features, then the best is to develop the correction on these features (step
c), and to merge again these features on the ongoing release: if by chance the release proves unviable, the at least the work done on these features is preserved. - Else, make the correction in the release itself (step
d).
Once the release qualified, it is tagged and merged into the stable branch (step e on the diagram).
The workflow is ready for the next iteration.
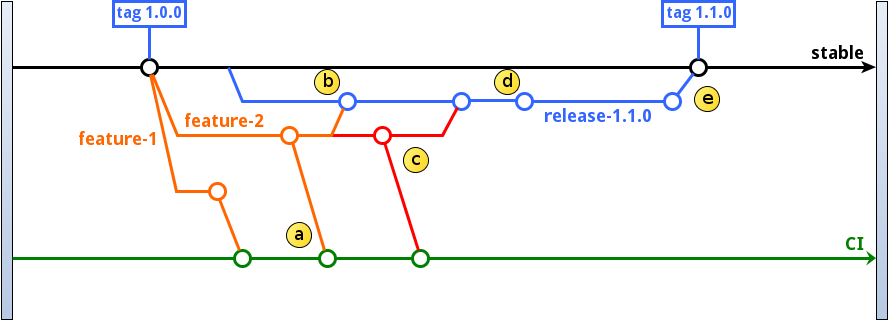
Some features created from the last stable node are merged into CI, then into the new release branch (step a on the diagram).
How to react if for incompatibility reasons or unmatured developments (here on feature-2) the release proves unviable (step b)?
The solution consists in closing the branch release-1.1.0 (step b), then creating a new release (step c) with only a subset of the tickets selected for the previous release.
Here feature-2 is ignored and feature-1 is merged into the new release (step d).
Once the release qualified, it is tagged and merged into the stable branch (step e on the diagram).
The branch feature-2, still part of CI branch, could still be corrected in the future and be part of a next release.

What to do prevent/limit divergence between the CI branch and the stable branch when the features committed into the first one are given up (ie they will never be part of a release, hence never be part of the stable branch) ?
If they are left in CI, the future features will have to be compliant with these abandoned features, which is not efficient.
CI and stable would start to diverge.
Lets suppose that feature feature-1 merged into CI (step a on the to diagrams below) is declared "dead" some time later.
Two solutions:
- Either an undo-commit can be done, i.e. it is possible to cancel the evolutions on the branch by starting its development again : in that case, you just have to merge it again into
CI(stepbon the diagram below).

- Or the undo-commit seems way too complex: in that case, we have to stop using this CI branch (step
bon the diagram below), and open an one starting for last stable node (branchCI2, stepc). All the features that are not already in a release (herefeature-2) then have to be merged into this new branch (stepd). You can skip merging the features that are part of the ongoing release, as on the one hand the release is under continuous integration, on the other hand every feature after this release will report evolutions ontoCI.

Is it a problem id 2 features created from the same last stable node happen to be correlated ?
For instance, feature-1 targets an evolution on part of the kernel while feature-2 is started in the meantime to develop features based on that same part of the kernel.
- The developer in charge of
feature-2can choose to develop without taking care offeature-1. The last developer to merge intoCIand the next release will have to solve the conflicts... - The developer of
feature-2can decide to mergefeature-1into its own branch to get the last progress done onfeature-1or to have more accurate tests in its own environment.
If dependency can be foreseen and you can allow not to start the 2 features in parallel, then it's better not to do it!
What to do if a critical bug occurs in production?
In the first case, out of the testing phase of a new release (case a of the diagram below), we decide to fix the bug immediately using a hotfix.
The process consists in creating a branch dedicated to fixing the problem, then merging it into the stable branch with a new tag, just before (case b) or just after (case b') having merged the fix into CI : this choice depends on the real emergency, it's compromise between speed and reliability...
The second case depicts the need of correction during the testing phase of a release (case c).
Then, the fix branch has to be merged into the one of the current release, then into CI.
As previously, merging into the stable branch can be done before or after these merge operations, depending on the emergency.
Beware, creating a hotfix can potentially impair reliability of the stable branche.
A hotfix should only be a few lines long.
Special attention is needed, and the next release (or the ongoing one) must test theses fixes very carefully (trivial cases excluded).

Sometimes subprojects are needed. And Redmine allows this notion. Then, instead of creating one branch per ticket of the subproject, we can choose to create only one, named by the subproject, and to develop the changes associated with the subproject tickets in this branch. This doesn't break the propsed Git workflow. It's more about a branch naming convention.
Same applies for Redmine sub-tasks.
Do we really need to handle trivial tickets, such as "spellchecking" the same way as the others? Couldn't we deal with them as hotfixes?
Tempting... But one of the strong assets of Git is the branch management! Indeed, with Git:
- creating a branch si fast and simple, and chaining the 2-3 commands to create a distant one and import it locally could completely be scripted (if not already done) ;
- merging branches is known to be easier and quicker than with SVN
In practice, it doesn't really cost time to deal with this kind of ticket the same way as the other ones.
The diagram below depicts a possible transition between a situation when everyone commits on the master branch and the case when the teams adopt the New Process:
- ideally the shift should occur right after a rollout in production, to be as close as possible of a stable point
- the master branch would be derived as the stable branch in order to mitigate the risk of bad commits, and the rollout would be tagged (step
b) - we would create the continuous integration branch (step
c) - the existing development branches not merged on master (here
dev3) would be derived as features (herefeature-2450) to match the new naming convention (stepd). The best would be to merge the new tag into these branches to better stick to the new process.
That being done, the workflow described above as the New Process (step e) can be applied.
![]()
As an example, here is the Git tree of a project before and after transition:
After:

The site nvie.com describes another model of development workflow here: A successful Git branching model. Here is a diagram copied from this link :

Analysis :
- (+) To ease usage of this method, a set of scripts has been developped: git-flow.
- (–) Branches "feature for future release" can benefit from continuous integration only on their isolated content, but if you want to go a step further and test them in a more general context where they are tested with si other features, then you have to wait till the releases preceding the one they should be merged into are validated, tagged and merged into "master" and "develop".
- (+/–) The branches "feature" and "feature for future release" are created from the dev branch: the code used for their creation is more recent than the one of the last tag, but not validated as stable, which can slow down development due to bugs or unreliabilities (sometimes severely, considering the fact that the person facing the bug is not necessarily the one writing the faulty code).
- (+) The naming convention for branches helps making the workflow simple to grasp and use.
- (–) The "features" branches exist only in local dev repositories (quoting : "Feature branches typically exist in developer repos only, not in origin."), whereas we want to have them in fine also in the remote repository to allow picking up the tickets for the next release. This explains why the git-flow scripts don't know how to deal with features on the remote repository.
- (–) If a release becomes non viable (broken feature, unstable merge, ...), we have to fix the problem: we cannot close this release to create another one with a subset of the features previously selected and leave the correction behind for a next release (cf. Unviable release).
- (+) If the development of a feature lasts, developers are encouraged to regularly merge the dev branch into their feature.