NISQA Training Datasets
NISQA is trained and evaluated on overall 81 datasets. These datasets come from different sources, such as the POLQA pool, ITU-T Supp. 23, and other internal datasets. We make available the NISQA Corpus, which contains 8 datasets that were specifically created for training and evaluating NISQA. An overview of all datasets that were used for training and evaluating the NISQA model weights (nisqa.tar) are given in the following as these details did not fit into the NISQA paper. The training datasets of the NISQA-TTS model are described in the Naturalness prediction paper.
The POLQA pool was set up for the ITU-T POLQA competition. In this competition, a successors model for the then ITU-T standard for speech quality prediction PESQ was developed and selected. In contrast to PESQ, POLQA was developed to estimate speech in a super-wideband context. Consequently, the pool contains a wide variety of super-wideband datasets from different sources that were created for training and validation of the POLQA model. It also contains older narrowband and wideband datasets that were used for the PESQ and the P.563 model. This dataset pool is not publicly available.
An overview of the 55 datasets can be seen in the table. A general description of these datasets can be found in Appendix II of ITU-T Rec. P.863. Overall the pool contains eight different languages: English, German, French, Swedish, Dutch, Czech, Chinese, and Japanese. The pool contains most common codecs used in telecommunication networks. However, it does not contain the more recent super-wideband codecs Opus and EVS. Among other conditions, the pool contains packet loss, amplitude clipping, different background noises, and live recordings. Only for the three super-wideband Swissqual datasets dimension speech quality ratings are available, which is indicated by the Dim column in the table.

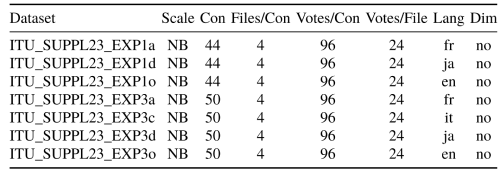
ITU-T P Suppl. 23 is an older pool of datasets, containing speech samples used in the characterization tests of the ITU-T 8 kbit/s codec G.729. It is one of the few publicly available speech quality dataset pools and therefore often used in literature. Overall, the pool contains ten datasets of which three sets are rated on a DCR scale. Only the seven datasets that were rated on an ACR scale are used. An overview of these datasets can be seen in following Table. They contain four different languages: English, French, Italian, and Japanese. All of the datasets are rated in a narrowband context and contain coded speech with frame loss and noise conditions.
Besides these two large pools and the new test set, also a set of other datasets from varies projects are used for training the model. An overview of these datasets can be seen in following table.

59 of these datasets were used for training the model. An overview of the training datasets and the achieved PCC is shown in the following table. The results on the validation and test datasets can be found in the NISQA paper.
